常駐先でLT会を90回以上継続した話
お約束
- 本記事は ARISE analytics Advent Calendar 2022 の2日目の記事です
- 昨日は tsukasaI さんの devcontainerでコンテナ内開発
- 明日は、mkkon さんの 【論文紹介】SignGAN【CVPR 2022】
はじめに
私が業務委託契約で常駐している ARISE analytics で、LT会を主催しております。90回以上はそれなりに継続できていると思いますので、どのように運用しているかなどを書いていこきます。*1 あくまでも私がARISEで行ったLT会であり、主催者や目的、環境により異なりますので、ポエムとして読んでいただければと思います。
LT会概要
- 基本週1開催
- 月曜12:00 - 13:00
- 業務外
- テーマなし
- 真面目な話、不真面目な話、業務の話、趣味の話なんでもあり
- 新型コロナ流行以降はリモート開催(Zoom)
実績
- 2019/11/1から2022/11/28までで93回
- のべ160回の発表
- 発表者47人
LTとは
LTを知らない人がいるかもなので最初に軽い説明。 LTはLightning Talks(ライトニングトーク)の略であり、5分から15分程度の短い発表のことを言います。IT業界では10年くらい前?からそれなりに流行っているという認識です。勉強会、カンファレンス等の主となる発表の後で行われることが多いです。まれにLT大会などとしてLTのみの勉強会などもありますね。
LTで発表するメリット
LTは通常の勉強会などの発表と比べると以下のようなメリットがあると思っています。
- 資料作成簡単
- 失敗 OK
- 人前で話すことに慣れる
- 反応を簡単に確認できる
- 自分が行動するためのトリガー
詳細は割愛しますが、発表時間が短いことから、1,2のメリットが発生し、その結果3,4,5が発生するというロジックです。
LTで発表するデメリット
反してデメリットは以下の通り。
- 内容が浅くなる
- 笑いを取りに行きがち
- 資料直前で作りがち
- 内容は短く簡潔そしてインパクト
1がほぼ全てですね。その結果2,3,4という感じです。 並べてみてもメリットが多いと考えているため、LTはタイミングが合えばなるべく発表する機会を作るようにしています。
LT会をはじめた理由
私がLT会をはじめた理由は以下の3点です。
- 人前で話すことに慣れる
- アウトプットの場
- コミュニケーション
全て 自分のため です。 自分のために自分が行う。ただ、参加者は多い方が楽しいですし、参加者が増えることでデメリットもない。(あえていうなら発表機会が減る) 参加者側にも上記したようなメリットもあるので、せっかくなら他の人もやる?っというスタンスです。
心がけたこと
LT会で心がけたことは以下の4点
- 無理はしない
- 発表のハードルを下げる
- 継続する
- 参加しやすくする
無理はしない
自分のためなので無理はする必要はありません。仕事が忙しいときはスキップ。業務内で行う許可も取らない。参加者も無理に増やそうとしない。自分が発表する場であることを忘れずに、強制力は発生しないように、周りへの気遣いはしない。っという事を気にしていました。 っというのも、やればわかるのですが自分のためとはいえ、週1開催はとても大変。好きでやっていて仕事でもないのに、資料作成、開催時間以外にはなるべく時間を割きたくないのです。
発表のハードルを下げる
自分のためでもあり、自分以外の発表者のためでもあります。 前職、前々職でもLT会を主催していましたが、正直参加者は集まりませんし増えません。(1回限りだと結構集まる)っとなると、必然的に自分で発表することが多くなるため、毎回しっかりとした資料を作り、役に立つ、心に響くような発表を行うことは不可能です!(ちなみに93開催で48回発表しています)話すこと、発表することが目的なので、内容は問わず、雑でも良い、資料なしも歓迎というスタンスで行っていました。話すことが正義です!
継続
↑で雑でもOKという事を書きましたが、つまり内容はとても薄いです。ただ、全体でみれば内容に得るものはあります。私自身としては内容が薄いと思っていても、ジュニアの方や別業種の方などには響いたりすることがよくありました。具体的にはエンジニアとしてのちょっとしたスキルは別業種の方に、私の過去の経験やキャリアの話はジュニアの方にという感じです。
参加しやすくする
あれ?↑で「自分のため」、「せっかくなら他の人もやる?のスタンス」とか言っていましたが、やっぱり聞いてくれる方は多い方が嬉しいですし、反応も多くなり、楽しいです。結局人は他人と関わることで喜びを覚える生き物なのです。
発表者を増やすこととしては、記載したハードルを下げること、チーム内で誘う、SlackでLTになりそうな内容には声をかけることを行っていました。聴講者側には告知を全体チャットで行うことくらい。
ただ、発表時には実況スレッドとしてSlackチャンネル内にスレッドを作り、質問、意見、思ったことなど気軽に書けるようにして、自分は積極的に反応をすることで、楽しい場であることは演出しています。
90回以上継続した感想
良かったこと
正直良かったことばかりです。
参加者多かった
上記したように、前職、前々職でもLT会を主催していたのですが、参加者は延べ10人程度で盛り上がっていたとはとてもいえない状態でした。ただ、今回は3,40人くらいの参加者がいた回もあり、私の所属部署以外からの参加も多数。特にコーポレート部門や、情報システム部など普段あまり交流のない部署の方も参加も多数ありました。
会社の規模や忙しさ(余裕)、新型コロナ流行によるリモート化などなど色々な要素が重なった結果だと思っています。
長く続いた
新型コロナ流行によるリモート化による中断(2020/02/28 - 2020/10/09)を挟み、3年間で93回開催、延べ160の発表があったのは長く続いたと言っても良いでしょう。新型コロナや、仕事やプライベートによる多忙、発表多めの方の離任、私自身が離任するかも話、などなど中断するタイミングは何度かあったものの、ここまで続いたのは発表者、聴講者として参加してくださった皆様の反応があったからだなと思います。自分のためとはいえ、自分の力だけでは継続は難しい。
社内で名前が売れた
参加者が多かった話のところでも書きましたが、様々な部署から参加してくれたことで社内で名前が売れました。たまに出社すると声かけられたり、挨拶しにきてくれたりなどという事もよくありました。*2
実況スレッド良かった
上記したことと重複しますが、実況スレッドはかなり良かったと思っています。リモート開催という事もあり、発表に対しての反応を確認できないことに対しての対応でしたが、聴講者側としても聞きたいことや感想を気軽に書き込めるため、LT会の盛りあがりに大きな影響を及ぼしていたと思います。
余談ですが、実況スレッドはリモートワークが中心の場合、LT会以外でも使える良い文化だと思っており、実際に部署や会社全体の会などでも使用されるようになりました。これらの場合は盛り上がるのもそうですが、集中してくれて内職が減るという効果もあると思っています。
LT会でもう少し改善できたこと
やはりもう少しうまくやれたかなという事はいくつかあります。
もう少し人集められた
頑張ることではないと思いつつも、参加者が多い日があるという事は少ない日もあるわけで、聴講者が私1人しかいない日には、主催者としてもう少し頑張った方が良いかなと思いました。*3
上の人に話してほしかった
どうしても接する機会が少ない役職者(一般役職でいうところの部長や課長位)の方に話してほしかった。それもくだらないことを。どうしても役職者との間には壁ができてしまうため、その壁を取り除くことをできたらと思っていたのですが、当たり前のように忙しいのもありあまり実現できませんでした。資料不要で趣味の話などと積極的に声かけても良かったなと思っております。
自社と合同でやってもよかったかも
仕事感がありますが、せっかくなら会社関係を良好に的な意味もあり、LT会に別の趣向をみたいな意味もあり、やってみても面白かったかもと思っております。*4 いや、さすがに業務感出てしまうので調整とかしなきゃなので面倒だったかもですね。難しい。
もっと真面目じゃない内容を増やしたかった
どうしても技術方面の真面目な内容が多くなり、くだらない内容のLTが少なかったです。ところどころで、クレーンゲームや鉄道、エアコン、富山、投資の話などがありましたが、絶対数としては少なかったです。これは主催であり主要発表者である私が技術方面の話がほとんどであったため、そういう方向になっていたというのはあると思います。 聞く方としては、業務の合間の休憩時間ということもあって不真面目の話を望んでいたのですが。。。
LT会のすゝめ
LT会は簡単に開催できますし、上記したように主催者も参加者も聴講者もメリットは多いです。週1でやれとは言わないので、是非1回開催して見てはどうでしょうか。また、もし社内でLT会を見かけたら気軽に参加してみてください。*5
みんなLTやろうぜ!
コメントされそうなこと(追記するかも)
- 自社でやらないの?
- 今年から月1でやってた
- ネタは業務に近いところから生まれるので、コードや環境など話せない内容が多いと厳しかった
- 資料どこにおいてる?
- 個人的には社外に置くことをすすめてましたが、発表管理等で使っていたConfluenceにみんな置いてた
- 私の資料は こちら (公開できないものもあるので数は合わない)
ユーザ認証でGoogleドライブ上のファイルをPythonで操作する
はじめに
- コードはドキュメント通りだが、認証に1日かかったためメモ
- 本記事ではユーザ認証を使用する
- バッチ処理などで使用するためにはサービスアカウントを使用する
- キャプチャはないが、参考リンクは大目に貼っているので、解決しない場合でもリンクは見てみることを推奨
前提
- ブラウザ上でファイルの取得は可能であることを確認
- privateのファイル
- 認証あり。インターネットに大公開しているファイルではない
- 認証関連の設定が終わった後のコードは↓の通り
- GCPへのアクセスが可能であること
- プロジェクトは作成済み
- gcloudコマンドを使用可能であること
手順
- Google Driv APIを有効にする
- 認証情報を作成
- https://console.cloud.google.com/apis/credentials
- 「+認証情報を作成」 → 「OAuthクライアントID」
- 初回はOAuth同意画面を設定する必要がある(projectも?)
- 認証画面で表示されるので自分だけが使うなら適当に設定。
- デスクトップアプリを選択
- 特に入力に悩むことはないと思われる
- 認証情報(JSON)をダウンロードし、適切な場所に配置
- 認証情報登録時の最後にダウンロードされる
- 認証情報の「OAuth 2.0 クライアントID」
- 下記のコマンドでデフォルト認証情報を設定
gcloud auth application-default login --scopes "https://www.googleapis.com/auth/drive" --client-id-file "認証情報.json"- https://cloud.google.com/sdk/gcloud/reference/auth/application-default/login
memo
gcloud auth application-default loginで作成される認証情報の格納PATH
参考
- LocalでApplication Default Credentialsを利用している時にG Suite APIやFirebase APIを実行するとgoogleapi: Error 403: Request had insufficient authentication scopes. になる
- OAuth 2.0 Scopes for Google APIs
- google.auth package
- Pythonライブラリの認証で使用するgoogle.auth.defaultのドキュメント
- 認証情報をどういう優先順位で取得するかは重要
- 今回はApplication Default Credentials(ADC)を使用するので2
- https://google-auth.readthedocs.io/en/latest/reference/google.auth.html
- Download files | Drive API | Google Developers
- 認証した後にファイルダウンロードする場合のコード
- https://developers.google.com/drive/api/guides/manage-downloads#python
- pythonからGoogleDriveAPIを叩く
- Application Default Credentials
- 認証の本質のドキュメントと思われる
- https://google.aip.dev/auth/4110
- Create access credentials
- 認証の公式ドキュメント。種類別に網羅。
- https://developers.google.com/workspace/guides/create-credentials
- Python Quickstart | Drive API | Google Developers'
- Drive APIをPythonで呼び出すドキュメント
- https://developers.google.com/drive/api/quickstart/python
- Python: download files from google drive using url
npm install と npm ci をどのように使い分けるか
※タイトルの npm install は引数なしを想定しています。
一言
- 引数なしの
npm installは使わない - 環境構築時には
npm ciを使用する
詳細
npm installnpm ci- 依存ライブラリの更新を定期的に行う場合、CIで
npm installをして更新があればpackage-lock.jsonをPRさせるのが良さそう。 - package.json自体の更新はdependabotを使うと良い。
きっかけ
- 引数なしの
npm installは package-lock.json を更新しないと思っていたが更新された(単純に記憶違い) - 各種環境構築スクリプトで
npm installが使われていたが、package-lock.json が更新されるため、差分が発生する - 社内で聞いたら教えてくれた↑↑の通り教えてくれた
参考URL
- What is the difference between "npm install" and "npm ci"?
- stackoverflow。凄いわかりやすい
- https://docs.npmjs.com/cli/v8/commands/npm-install
- https://docs.npmjs.com/cli/v8/commands/npm-ci
追記(2022/05/28)
id:efcl から以下のブコメをもらったので追記。(よくわかっていないのでそのうちもう少し調べる)
npm install と npm ci をどのように使い分けるか - 山pの楽しいお勉強生活b.hatena.ne.jp
- [npm]
引数なしの`npm install`がpackage-lock.jsonを更新するかは、npmのバージョンで動作が異なる感じ。 <a href="https://github.com/azu/npm-install-update-package-lock/actions/runs/2399517030" target="_blank" rel="noopener nofollow">https://github.com/azu/npm-install-update-package-lock/actions/runs/2399517030</a> <a href="https://github.com/npm/rfcs/issues/415#issuecomment-938279066" target="_blank" rel="noopener nofollow">https://github.com/npm/rfcs/issues/415#issuecomment-938279066</a>
2022/05/28 10:44
- azuさんのGitHub Actionsの結果を見ると、npm6とnpm8で
npm installをした結果、npm6はlockファイル内の依存ライブラリのバージョンが変更されているが、npm8は変わっていなかった。 - 2つ目のリンクの内容はよくわからない
- 少し調べたところ、npm7からlockファイルのバージョンが上がり、
npm installを行った際にバージョン2に書き換わるらしいのだが関係ある?
PySparkでDataFrame.cacheはMEMORY_AND_DISKレベルキャッシュされる
概要
- タイトルが全て
- MEMORY_ONLYだと勘違いしていたためメモ
- persistも引数なしで呼び出すとMEMORY_AND_DISKなので同じ
※2021/12/17時点の最新版であるPySpark3.2.0の情報です
詳細
- レベルの変更の歴史
pyspark.sql.DataFrame.cacheがPySpark1.3.0で追加されたときは「MEMORY_ONLY_SER」レベル- 2.0.0で「MEMORY_ONLY」レベルに変更
- 2.1.0で「MEMORY_AND_DISK」レベルに変更
- ドキュメントに以下の記載があるのでScalaでは2.0から「MEMORY_AND_DISK」レベルだったようです
The default storage level has changed to MEMORY_AND_DISK to match Scala in 2.0.
- persistメソッドに指定できるレベルは以下を参照
Xiaomi Pad 5(MIUI12)を複数アカウント(ユーザー)で使用する
はじめに
- Xiaomi Pad5を購入したものの、デフォルトでは複数ユーザーで使用ができない?
- 端末というより、OSであるMIUIの仕様?
- とりあえず複数ユーザーで使用できるようになったので手順をメモする
- ただし、色々制限はかかっているの注意。詳細は下記参照
- 他にも良い手順があったらコメントでもTwitterでも良いので教えて下さい
わかる人向けの手順概要
※よくわからない人は下記にキャプチャ付きの詳細手順あります。
- 設定 → デバイス情報
- MIUIバージョンを10回タップ
- 開発者向けオプションを有効
- 追加設定 → 開発者向けオプション
- デフォルト値にリセット
- ※全然関係ない項目のように見えるがここが一番のハマりポイント
- 最下部のMIUI最適化をオフ
- 複数ユーザー → 追加
- 切り替え
- Google関連の設定はOFFにして初期設定をする
よくわかっていないこと(困っていること)
- ログイン時に追加したマルチユーザーでログインできない
- 所有者(管理者)でログイン後に、設定からユーザを切り替える必要がある
- Activity Launcher というアプリでユーザの切り替えのショートカットを作ることでとりあえずは対応
- 追加したユーザーの初期設定でインターネットに繋がらない
- Google関連の設定をONにして初期設定をするを行うと永遠に終わらない
詳細手順
- 設定 → デバイス情報 を表示
- MIUIバージョンを10回タップ

- 何回かタップしていると「デベロッパーになるまであとXステップです。」と表示される。

- 規定回タップすると「これでデベロッパーになりました!」と表示される。
- 追加設定内に「開発者向けオプション」が表示されているのでタップ
- 開発者向けオプション内のデフォルト値にリセットを複数回タップする
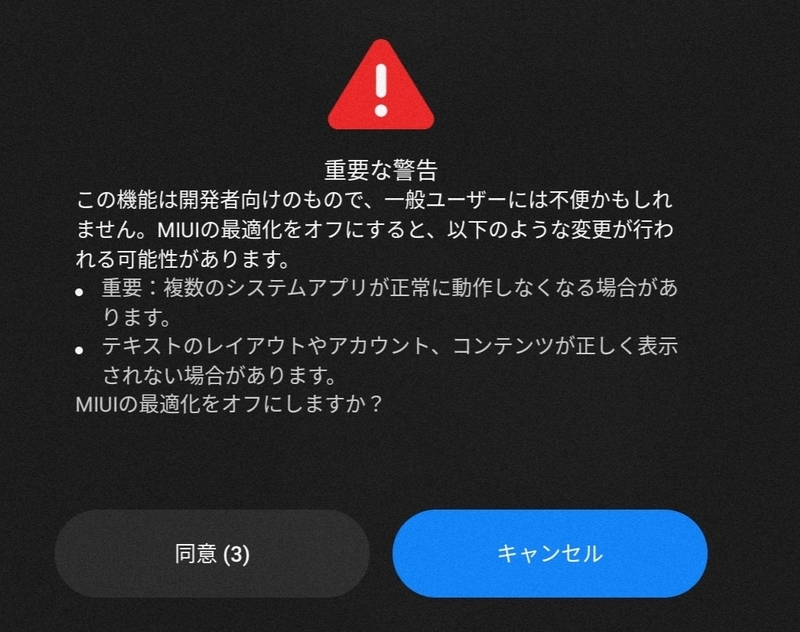
- ここからが本記事のキモ。私の環境だと「MIUIの最適化をオンにする」が表示されなかったので以下の操作を行う。

- 「自動入力の開発者向けオプションをリセットしました」と表示される。
- この設定は自動入力の設定なのでこの表示は正しい

- 何回かタップしていると「MIUIの最適化をオンにする」が表示されるのでオフに切り替える
- 重要な警告を熟読してから同意
- 複数ユーザーという項目が追加されているので選択
- オンに切り替え
- ユーザーまたはプロファイルを追加 → ユーザを追加する。
- 追加されたユーザをタップして切り替える
- ユーザの初期設定で「 Google関連の設定はOFF」にする





参考
GitHub ActionsでビルドしたドキュメントをGitHub Pagesで表示する
まとめ
- GitHub Pagesは「GitHub Enterprise Cloud 」プランの場合privateで使用する事ができる
企業でお金払っていてオンプレのGitHubでなければこのプランのはず- 追記: 有料プランでもTeamプランというのがありました。こちらではアクセス制御はできません
- GitHub ActionsでbuildしたドキュメントをGitHub Pagesに簡単に反映可能
- peaceiris/actions-gh-pagesというGitHub Actionsが便利すぎる
- ほぼ無料
はじめに
GitHub Pagesの存在は知っていてもprivateリポジトリで使用できないと思っている方は多いと思いますが、2021/01/21より「GitHub Enterprise Cloud 」であればprivateリポジトリで使用できるようになっています。(正確にはアクセス制御ができるようになった)
変更方法などは以下のドキュメントを参照
とは言え、GitHub Pagesの管理はそれなりに面倒です。 そこで、GitHub Actionsを併用する事でGitHubのイベントをトリガーにしてGitHub Pagesを簡単に更新する事ができたのでまとめておきます。
よくある問題
- CIでドキュメントをビルドしているが有効活用されない
- ビルドしたドキュメントを置く場所がない
- ビルドしたドキュメントにアクセスするのが面倒
手順
具体的なサンプル
- masterやdevelopブランチでhtmlを変更すると<ブランチ名.html>というファイル名でGitHub Pagesにコミットする
- https://github.com/yamap55/doc_github_pages_deploy
- GitHub Actionsの設定
- 業務では静的なhtmlではなくyamlから生成したhtmlをコミットするようにしている
- pytestのカバレッジをGitHub Pagesにコミットする
- https://github.com/yamap55/pytest_cov_github_pages
- GItHub Actionsの設定
- 本当はCoverallsやCodecov、Code Climate などのサービスを使いたいのだけど。。。
注意点
- privateリポジトリで使用する場合にはURLが「
http(s)://<username>.github.io/<repository>」、「http(s)://<organization>.github.io/<repository>」の形式ではない- GitHub Pages サイトの可視性を変更する - GitHub Docs
- ただ、ドメインを割り当てることができるらしい
参考
- 公式ドキュメントはかなり充実しています
PySparkではDataFrameのjoinでorderは維持されない
概要
- PySparkのDataFrameではjoinした際にorderは維持されない
- 正確にはshuffleが行われる
- orderは出力直前に行うのが鉄則
再現コード
from pyspark.sql import SparkSession spark = SparkSession.builder.getOrCreate() df1 = spark.createDataFrame( [ ['user_01'], ['user_02'], ['user_03'], ['user_04'], ['user_05'], ], ['id'], ) df2 = spark.createDataFrame( [ ['user_01', '1'], ['user_02', '2'], ['user_03', '3'], ['user_04', '4'], ['user_05', '5'], ], ['id', 'c1'] ) print('order byされているdf1') df1 = df1.orderBy('id') df1.show() print('order byされているdf2') df2 = df2.orderBy('id') df2.show() print('join後') df1.join(df2, 'id').show()
order byされているdf1 +-------+ | id| +-------+ |user_01| |user_02| |user_03| |user_04| |user_05| +-------+ order byされているdf2 +-------+---+ | id| c1| +-------+---+ |user_01| 1| |user_02| 2| |user_03| 3| |user_04| 4| |user_05| 5| +-------+---+ join後 +-------+---+ | id| c1| +-------+---+ |user_03| 3| |user_02| 2| |user_01| 1| |user_04| 4| |user_05| 5| +-------+---+
参考
- Shuffle operations
- join spark dataframes rows order