WSLのUbuntuを 20.04 から 24.04 に移行したメモ

はじめに
WSLでUbuntuの20.04を使用していましたが、標準サポートが2025/04までということなので24.04に入れ替えます。 バージョンアップもできるようですが、ほぼ開発環境としか使っていないのでどうせなら新規作成してデータを移し替える方法を選びました。
一応 ChatGPT 4oに聞いてみたら以下の回答が返ってきました。 が、裏は取っていないので真偽は不明です。
WSLでは「そのままUbuntuのバージョンアップをする方法(do-release-upgrade)」も一応可能ですが、非推奨です。 なぜバージョンアップは非推奨か WSLのUbuntuは「軽量・仮想環境」として設計されており、do-release-upgrade は公式に完全なサポート対象ではありません。 WSL特有の設定(systemd まわりや init、ネットワーク)などが壊れることがあります。 WSLの新規インストールは非常に軽いため、「まっさらな22.04や24.04をインストール」→「必要なデータだけ移す」方が安全で確実です。
WSLにUbuntu 24.04をインストール
- コマンドプロンプトを起動
- 現在の状態を確認
C:\Users\yamap>wsl -l Linux 用 Windows サブシステム ディストリビューション: Ubuntu-20.04 (既定) docker-desktop
- Ubuntu 24.04をインストール
C:\Users\yamap>wsl --install -d Ubuntu-24.04 ダウンロード中: Ubuntu 24.04 LTS インストール中: Ubuntu 24.04 LTS ディストリビューションが正常にインストールされました。'wsl.exe -d Ubuntu-24.04' を使用して起動できます
- インストールされていることを確認
C:\Users\yamap>wsl -l Linux 用 Windows サブシステム ディストリビューション: Ubuntu-20.04 (既定) Ubuntu-24.04 docker-desktop
Ubuntu 24.04の設定
- Ubuntu 24.04に接続
- ユーザー名とかパスワードを聞かれるので設定
C:\Users\yamap>wsl -d Ubuntu-24.04 Provisioning the new WSL instance Ubuntu-24.04 This might take a while... Create a default Unix user account: yamap New password: Retype new password: passwd: password updated successfully To run a command as administrator (user "root"), use "sudo <command>". See "man sudo_root" for details. Welcome to Ubuntu 24.04.2 LTS (GNU/Linux 5.15.167.4-microsoft-standard-WSL2 x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/pro System information as of Sat May 10 10:34:33 JST 2025 System load: 0.13 Processes: 34 Usage of /: 0.1% of 1006.85GB Users logged in: 0 Memory usage: 26% IPv4 address for eth0: 192.168.61.63 Swap usage: 0% This message is shown once a day. To disable it please create the /home/yamap/.hushlogin file. yamap@yamap-thinkpad:/mnt/c/Users/yamap$
- ホーム
yamap@yamap-thinkpad:/mnt/c/Users/yamap$ cd ~ yamap@yamap-thinkpad:~$ ls -la total 28 drwxr-x--- 4 yamap yamap 4096 May 10 10:34 . drwxr-xr-x 3 root root 4096 May 10 10:34 .. -rw-r--r-- 1 yamap yamap 220 May 10 10:34 .bash_logout -rw-r--r-- 1 yamap yamap 3771 May 10 10:34 .bashrc drwx------ 2 yamap yamap 4096 May 10 10:34 .cache drwxr-xr-x 2 yamap yamap 4096 May 10 10:34 .landscape -rw-r--r-- 1 yamap yamap 0 May 10 10:34 .motd_shown -rw-r--r-- 1 yamap yamap 807 May 10 10:34 .profile
- インストール済みの各種ツールをアップデート
yamap@yamap-thinkpad:~$ sudo apt update [sudo] password for yamap: Hit:1 http://archive.ubuntu.com/ubuntu noble InRelease Get:2 http://security.ubuntu.com/ubuntu noble-security InRelease [126 kB] Get:3 http://archive.ubuntu.com/ubuntu noble-updates InRelease [126 kB] Get:4 http://archive.ubuntu.com/ubuntu noble-backports InRelease [126 kB] Get:5 http://security.ubuntu.com/ubuntu noble-security/main amd64 Packages [820 kB] Get:6 http://archive.ubuntu.com/ubuntu noble/universe amd64 Packages [15.0 MB] (省略) Get:55 http://archive.ubuntu.com/ubuntu noble-backports/multiverse amd64 Components [212 B] Get:56 http://archive.ubuntu.com/ubuntu noble-backports/multiverse amd64 c-n-f Metadata [116 B] Fetched 34.0 MB in 6s (6158 kB/s) Reading package lists... Done Building dependency tree... Done Reading state information... Done 99 packages can be upgraded. Run 'apt list --upgradable' to see them.
yamap@yamap-thinkpad:~$ sudo apt upgrade -y Reading package lists... Done Building dependency tree... Done Reading state information... Done Calculating upgrade... Done The following packages will be upgraded: (省略) Processing triggers for libglib2.0-0t64:amd64 (2.80.0-6ubuntu3.2) ... Processing triggers for dbus (1.14.10-4ubuntu4.1) ... Setting up libgtk-3-0t64:amd64 (3.24.41-4ubuntu1.3) ... Setting up libgtk-3-bin (3.24.41-4ubuntu1.3) ... Processing triggers for libc-bin (2.39-0ubuntu8.4) ... yamap@yamap-thinkpad:~$
- 文字コードを変更
yamap:~ $ sudo dpkg-reconfigure locales [sudo] password for yamap: Generating locales (this might take a while)... ja_JP.UTF-8... done
※ ja_JP.UTF-8 UTF-8 をspaceで選択してOK
- デフォルトエディタをvimに変更
yamap@yamap-thinkpad:~$ sudo update-alternatives --config editor There are 4 choices for the alternative editor (providing /usr/bin/editor). Selection Path Priority Status ------------------------------------------------------------ * 0 /bin/nano 40 auto mode 1 /bin/ed -100 manual mode 2 /bin/nano 40 manual mode 3 /usr/bin/vim.basic 30 manual mode 4 /usr/bin/vim.tiny 15 manual mode Press <enter> to keep the current choice[*], or type selection number: 3 update-alternatives: using /usr/bin/vim.basic to provide /usr/bin/editor (editor) in manual mode
.bashrc の更新
wget --progress=dot:giga https://raw.githubusercontent.com/git/git/master/contrib/completion/git-completion.bash -O ~/.git-completion.bash wget --progress=dot:giga https://raw.githubusercontent.com/git/git/master/contrib/completion/git-prompt.sh -O ~/.git-prompt.sh chmod a+x ~/.git-completion.bash chmod a+x ~/.git-prompt.sh
※Gitの各種情報表示のためのシェル
vi ~/.bashrc
source ~/.git-completion.bash
source ~/.git-prompt.sh
export PS1='\[\033[1;30m\]\t\[\033[0m\] \[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\[\033[1;30m\]$(__git_ps1)\[\033[0m\] \$ '
function clip() {
cat - | iconv -t utf-16le | "/mnt/c/Windows/system32/clip.exe"
}
export LANG=ja_JP.UTF-8
export LC_TIME=ja_JP.UTF-8
※ターミナルにGit関連情報の表示したり色付けたり、クリップボードで絵文字の文字化けを修正したり、日本語の設定とか
必要なものをインストール
※Docker内で作業することがほとんどなので少ない。。。
- Python
sudo apt update sudo apt install -y python3 python3-pip python3-venv python-is-python3
※2025/05/10の段階だと3.12.3がインストールされる
- nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
DNS設定変更
WSLではネットワークによってはDNSが正しく機能しないことがあるため、手動で安定した設定にする
※2025/05/10の時点では有効ではあるが将来はわからない WSLのIssue に最新情報が書き込まれる可能性が高いので参照すること
- DNS設定の自動生成を停止
- 設定ファイルを開く(
sudo vi /etc/wsl.conf) - 以下を記載
- 設定ファイルを開く(
[network] generateResolvConf = false
- DNSを手動設定
- 自動生成された
/etc/resolv.confを削除 - 設定ファイルを作成(
sudo vi /etc/resolv.conf) - 以下を記載
- 自動生成された
nameserver 8.8.8.8
※8.8.8.8 は Google Public DNSサーバー (Public DNS | Google for Developers)
必要なデータを移行
- Ubuntu 20.04 環境
cd ~ tar czf /mnt/c/Users/yamap/backup-settings.tar.gz .bash_profile .gitconfig .ssh
- Ubuntu 24.04 環境
tar xzf /mnt/c/Users/yamap/backup-settings.tar.gz
WSLのデフォルトを変更
ホストのコマンドプロンプトで以下を実行
- 設定
wsl --set-default Ubuntu-24.04
- 確認
wsl -l
Docker Desktopの設定変更
dockerコマンドをWSL内で使用するためにホストのDocker Desktop側で設定変更する
- 設定 → Resources → WSL Integration → 「Ubuntu-24.04」をON → Apply & restart

ファイルの移行
WSL の Ubuntu 環境を移行する際、rsync を使って一度 Windows 側に退避させてから戻すことで、高速にファイルを移動できます
ただし、Git 管理リポジトリを含むディレクトリを /mnt/c(NTFS)経由で rsync -a すると、
ファイルの実行ビット(permission)が壊れる可能性があるため注意が必要です
そのため、permission / owner / group を引き継がないオプションを付けて実行します
Ubuntu 20.04側(バックアップ)
rsync -av \ --no-perms --no-owner --no-group \ --exclude ".venv" \ --exclude "node_modules" \ --exclude "__pycache__" \ --exclude ".pytest_cache" \ --exclude "hoge/work/" \ ~/github/ /mnt/c/backup/github/
Ubuntu 24.04 側(復元)
rsync -av \ --no-perms --no-owner --no-group \ /mnt/c/backup/github/ ~/github/
Googleカレンダーの当日予定をGASでSlackに通知する
はじめに
Slackでまとめて当日の予定を送っていたのだが、使用していたGoogle Calendarアプリが2024/09/01で終了するらしいということを知った。


で、新しいGoogle Calendarでやり方を色々調べたがどうやら当日の予定を送る方法がみつからなかったので作った
GASのコード
※わかる人向けにとりあえずコード
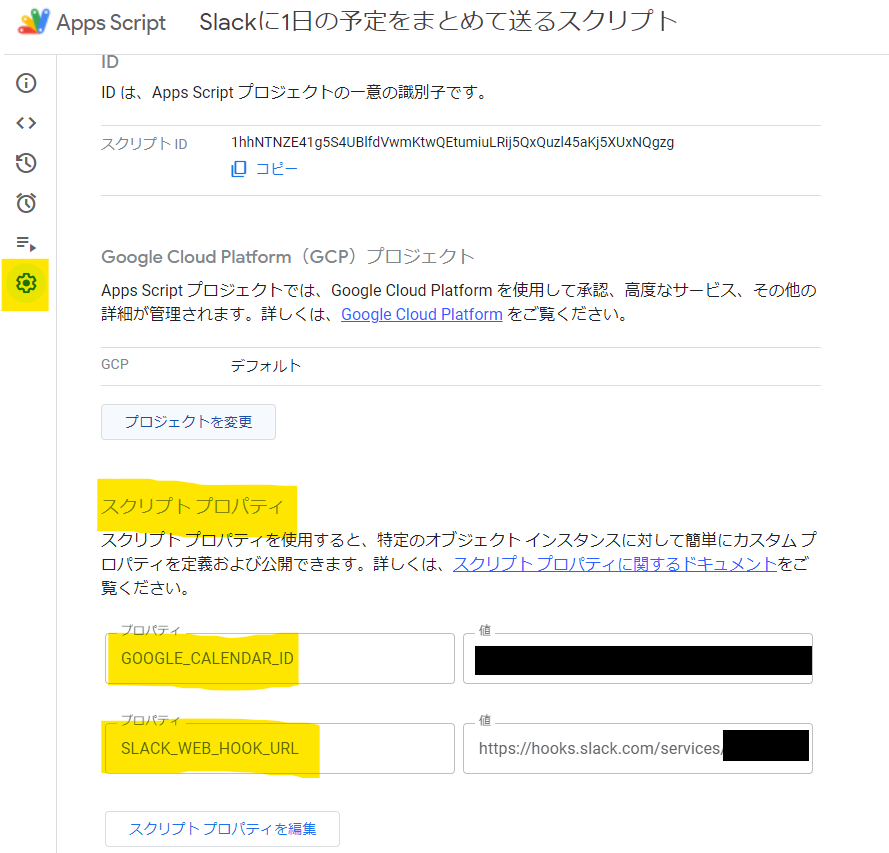
/** * @param {string} calendarID * @param {Date} targetDate */ function getEvents_(calendarID, targetDate) { const events = CalendarApp.getCalendarById(calendarID).getEventsForDay(targetDate) return events } function createToday_() { const now = new Date() return new Date(now.getFullYear(), now.getMonth(), now.getDate()) } /** * @param {Date} targetDate */ function convertHHMM_(targetDate) { return Utilities.formatDate(targetDate, Session.getScriptTimeZone(), "HH:mm"); } /** * @param {CalendarApp.CalendarEvent[]} events */ function convertEvents_(events) { return events.map((event)=> `${event.getTitle()}: ${convertHHMM_(event.getStartTime())} - ${convertHHMM_(event.getEndTime())}`) } /** * @param {string} url * @param {string} title * @param {string[]} messages */ function sendSlack_(url, title, messages) { const sendMessage = `${title}\n\n ${messages.join("\n")}` const json = { "text": sendMessage }; const options = { "method": "post", "contentType": "application/json", "payload": JSON.stringify(json) }; UrlFetchApp.fetch(url, options); } function main() { // スクリプトプロパティに必要な情報を設定していること // https://developers.google.com/apps-script/guides/properties?hl=ja const scriptProperties = PropertiesService.getScriptProperties(); const slackWebhookUrl = scriptProperties.getProperty("SLACK_WEB_HOOK_URL"); const calendarID = scriptProperties.getProperty("GOOGLE_CALENDAR_ID"); const events = getEvents_(calendarID, createToday_()) const convertedEvents = convertEvents_(events) const title = convertedEvents.length ? "■本日の予定" : "■本日の予定はありません" sendSlack_(slackWebhookUrl, title, convertedEvents) }
手順概要
必要なもの
- 通知したいカレンダーのID
手順
- Slackでアプリ作る
- WebhookのURLを取得
- カレンダーのIDを取得
- GASを新規作成
- スクリプトプロパティにWebhookのURLとカレンダーIDを追加
- ↑のコードをGASに張り付ける
- mainを実行して動作確認
- 毎日実行するようにトリガーを設定
手順詳細
※雑に記載
Slackでアプリ作る、WebhookのURLを取得
アプリ作る api.slack.com

Bot User作る
- Incoming Webhooks を有効化してURLを作成

カレンダーのIDを取得
- Googleカレンダーを開く
- 通知したいカレンダー右クリック → 設定と共有
- 下の方にカレンダーIDとして表示されている
xxxxxx@group.calendar.google.com

GAS
- Googleドライブ → 新規 → その他 → Google Apps Script
- 直接開けるURLあった気がしますが見つからず

- ⚙️ → スクリプトプロパティ → 「SLACK_WEB_HOOK_URL」、「GOOGLE_CALENDAR_ID」を追加
- コードを張り付け
- mainを実行して動作確認
- ⏰→ トリガーを追加
- 毎日実行するようにトリガーを設定


Dev Cointaerでデスクトップアプリを作る
はじめに
- Dev Containerはコンテナ内で開発するため、画面がなくウインドウを表示することができません
- CLIやWebを作る場合には特に問題となりませんが、デスクトップアプリを作るためにはウインドウは必須です
- 本記事ではX Window SystemであるVcXsrvを利用した方法でコンテナ内で起動したデスクトップアプリをホスト側で表示する手順を記載します
結論
- VcXsrvをインストールすればOK
環境
手順
- VcXsrvのインストール
- GitHubのリリースからインストーラーを取得
- Releases · marchaesen/vcxsrv · GitHub
- 今回は
vcxsrv-64.21.1.10.0.installer.exeを使用 - 久しぶりに古き良きインストーラーでインストールした気がする
- GitHubのリリースからインストーラーを取得

VcXsrvのバージョンについて
2024/05/12現在の最新版はsourceforge、GitHubともに21.1.10となっている、ただ、wingetは1.20.14.0。かなりバージョンが低いように見えるが、このバージョンは最新の1つ前である様子。ただ、1.20.14.0は2022年、21.1.10は2024年のリリースなので、本来はwingetでインストールしたいものの今回は最新版である21.1.10を利用することとした。
試す(tkinter)
以下のコードをDev Container内で実行する
"""main""" import tkinter as tk def main(): """メイン関数""" # メインウィンドウを作成 root = tk.Tk() root.title("simple desktop app title") # ラベルウィジェットを作成して配置 label = tk.Label(root, text="HELLO WORLD", font=("Arial", 24)) label.pack(expand=True) # GUIを開始 root.mainloop() if __name__ == "__main__": main()
ホスト側に表示される

リポジトリは以下の通り
GitHub - yamap55/devcontainer_desktop_app_sample
試す(Tauri)
コードは割愛

感想とか
DISPLAY環境変数やポート等の設定が必要になると思っていた。っというか、事前調査だと必要なはずだった。が、VS Code(Remote拡張?)かWSLのおかげで特に何もいらなかった。。。 っというか、これならblog書く必要すらなかったと思ったが、せっかく書いたので公開する。
Jupyter Notebook上でDjangoを動かす
はじめに
ちょっとQuerySetの動きをみたいとか、特定のコードを動かしたいとかあるよね?Django Shellでもいいのだけど、色々試したいからちょっと面倒なのでJupyter Notebookで動かしたい。 前職でも似たようなことをやっていてその時のスニペットをメモしていなくて地味に困っていたのだけど、時間ができたので再度作成しました。 もっと短かった気もするのだけど、とりあえず動くのでOK
コード
import os import django # https://docs.djangoproject.com/en/3.2/topics/async/#envvar-DJANGO_ALLOW_ASYNC_UNSAFE os.environ["DJANGO_ALLOW_ASYNC_UNSAFE"] = "true" os.environ.setdefault("DJANGO_SETTINGS_MODULE", "api.settings") django.setup()
上記のコードで設定が完了。次のセルでQuerySetなどが動きます。
from your_app_name.models import YourModelName YourModelName.objects.all()
キャプチャ

DJANGO_ALLOW_ASYNC_UNSAFE について
- コード上にコメント入れているけど、
DJANGO_ALLOW_ASYNC_UNSAFEを有効にしています - あくまでも開発時に少し試したいという時のコードなので問題はないはず
- 詳細はドキュメント参照
- 「はじめに」にも書いたけど前職のときのスニペットはこれは設定していなかった気がする
- 設定しない場合には以下のエラーが発生する(ドキュメントの通り)

SynchronousOnlyOperation
ログ全文はこちらクリック
---------------------------------------------------------------------------
SynchronousOnlyOperation Traceback (most recent call last)
Cell In[1], line 12
8 django.setup()
10 from api.modules.user.models import User
---> 12 User.objects.filter(email="a@example.com").exists()
File /usr/local/lib/python3.9/site-packages/django/db/models/query.py:808, in QuerySet.exists(self)
806 def exists(self):
807 if self._result_cache is None:
--> 808 return self.query.has_results(using=self.db)
809 return bool(self._result_cache)
File /usr/local/lib/python3.9/site-packages/django/db/models/sql/query.py:550, in Query.has_results(self, using)
548 q = self.exists(using)
549 compiler = q.get_compiler(using=using)
--> 550 return compiler.has_results()
File /usr/local/lib/python3.9/site-packages/django/db/models/sql/compiler.py:1145, in SQLCompiler.has_results(self)
1140 def has_results(self):
1141 """
1142 Backends (e.g. NoSQL) can override this in order to use optimized
1143 versions of "query has any results."
1144 """
-> 1145 return bool(self.execute_sql(SINGLE))
File /usr/local/lib/python3.9/site-packages/django/db/models/sql/compiler.py:1173, in SQLCompiler.execute_sql(self, result_type, chunked_fetch, chunk_size)
1171 cursor = self.connection.chunked_cursor()
1172 else:
-> 1173 cursor = self.connection.cursor()
1174 try:
1175 cursor.execute(sql, params)
File /usr/local/lib/python3.9/site-packages/django/utils/asyncio.py:24, in async_unsafe.<locals>.decorator.<locals>.inner(*args, **kwargs)
22 else:
23 if event_loop.is_running():
---> 24 raise SynchronousOnlyOperation(message)
25 # Pass onwards.
26 return func(*args, **kwargs)
SynchronousOnlyOperation: You cannot call this from an async context - use a thread or sync_to_async.
sync_to_async を使うと DJANGO_ALLOW_ASYNC_UNSAFE が不要
import os import django # type: ignore from asgiref.sync import sync_to_async # type: ignore os.environ.setdefault("DJANGO_SETTINGS_MODULE", "api.settings") django.setup() from api.modules.user.models import User @sync_to_async def check_user_exists(): return User.objects.filter(email="a@example.com").exists() await check_user_exists()
上記のように sync_to_async を使用することで同期を正しくとって安全に動かすことも可能。っというかこちらがあるべきの実装になる。が、繰り返しになるが今回は開発時など一時的に使用することを目的とするため、こちらはあまり使うことはないかなと思った次第です。
Dev ContainerでVS Codeの拡張機能がインストールされない場合に手動でインストールする
はじめに
- VS CodeでDev Containerを使う場合、
.devcontainer/devcontainer.jsonに拡張機能を書いておくことで自動でインストールされます - ただ、何らかの理由によりインストールされない場合が稀によくあります
- 割と長くDev Container使っていますが、理由は不明です。わかる人教えてください。
- 再度開いたりするとうまくいく場合もあるので、私の環境問題なのかもしれない
- 私の環境は大体Python入っているのでPythonで記載
Pythonコード
import json import subprocess from pathlib import Path p = Path(".devcontainer/devcontainer.json") with open(p) as f: jsonc_data = f.read() json_data = "\n".join(line for line in jsonc_data.split("\n") if not line.strip().startswith("//")) for extension in json.loads(json_data)["customizations"]["vscode"]["extensions"]: subprocess.run(["code", "--install-extension", extension])
※多分バージョン関係ないですが、3.11.9で動作確認済み
※jupyter notebookで動作させる場合、 "jupyter.notebookFileRoot": "${workspaceFolder}" を設定するか、devcontainer.json のPATHを変更する必要あるかも
Bash
#!/bin/bash
# JSONC形式のファイルパス
JSONC_FILE=".devcontainer/devcontainer.json"
# コメントを削除したJSONを生成する一時ファイル
TEMP_JSON_FILE=$(mktemp)
# JSONC形式のコメントを削除してJSONに変換
grep -v '^\s*//' "$JSONC_FILE" > "$TEMP_JSON_FILE"
# VS Codeの拡張機能をインストール
extensions=$(jq -r '.customizations.vscode.extensions[]' "$TEMP_JSON_FILE")
for extension in $extensions; do
code --install-extension "$extension"
done
# 一時ファイルを削除
rm "$TEMP_JSON_FILE"
※Chat GPTさんに作成してもらったので詳細は割愛
※ jq コマンドが必要
bashのワンライナー
JSONC_FILE=".devcontainer/devcontainer.json"; TEMP_JSON_FILE=$(mktemp); grep -v '^\s*//' "$JSONC_FILE" > "$TEMP_JSON_FILE"; extensions=$(jq -r '.customizations.vscode.extensions[]' "$TEMP_JSON_FILE"); for extension in $extensions; do code --install-extension "$extension"; done; rm "$TEMP_JSON_FILE"
※Chat GPTさんに作成してもらったので詳細は割愛
※ jq コマンドが必要
転職して1年経ったまとめと2023年の振り返り

はじめに
この記事は2023年の振り返りをすることで2024年に気合を入れようという記事、ポエムです。40代のITエンジニアがどういうこと考えて日々を過ごしているのかは少しわかるかも。ITエンジニアチックな話は少なめです。
何日かに分けて書いていたら7000文字弱という文字数になってしまった。それだけ盛り盛りの1年だったということで良いことです。
ベンチャー企業への転職
2023年の1月から株式会社STYZへ転職しました。Syncable という非営利組織向けの寄付プラットフォームサービスを開発しています。創業8年目で40人くらいの会社です。メンバーの全体的に若く、経営陣含めても私が最年長です。転職したきっかけは一緒に働きたいと思っていた人に誘われたため。
今までの所属企業も大企業(従業員1000人以上)のみいうことではなかったですが、最低でも100人以上所属 OR 大企業の子会社だったので会社内部制度等の会社としてあるべきこと?は大体揃っていて運用されているっという状態でした。これも振り返ってみればそう思うというだけで、当時はそんなこと考えてもみなかった。
で、転職してみたらあって当たり前、やってくれて当たり前と思っていたことが多いこと多いこと。これはITエンジニアとして、開発業務は勿論。会社の制度やオフィスそのもの、物品、会社として?社員として?みたいなことなどなど様々です。具体的に書けることはあまりないのですが、誰かがやってくれてたんだなということがとても多く、自分でやらなければならないこと、やり方が決まっていないこと、誰もやっていないこと、そもそもモノがない。そんなことばかり。
ただ、話を聞くと、チーム、会社としては必要。誰かがやらなければならない。やり方を決めなければならないという。っという意識はあるが手が回っていないという状況です。これらを率先して拾っていくことで、経営陣、若い方、中堅、ベテランの方問わずにこいつなんか色々やってくれるぞ?っと思われて信頼貯金の形成に大きく役立ったと思います。拾い方としても「XX探してもみつからないのですがありますか?ないならとりあえず決めちゃうのでレビューお願いします。」みたいな感じでさっさと動いちゃうと、自分のやりやすい形、慣れている形で決めることができるのでとても楽でした。上位者が気になる点あれば後で突っ込んでくれますし。(突っ込みなかったら全体に展開するだけ)
そしてこういう動きをしているとやたら褒められる!!今の会社で一番好きなのはみんな褒めてくれるとこです。大好きです。この文章を書きながら、私はこんなに褒めてもらって喜んでいるのに、皆を褒めているのか?と気づいてしまったので、2024年は良いところ、嬉しかったことは褒めていくことを心がけていきます。
メンバーの会社への共感度
会社のビジョンは「あらゆる境遇を打破できる社会」、ミッションは「民間から多種多様な社会保障を行き渡らせる」というものです。若い会社だからか事業が社会貢献性が高いからなのかはわかりませんが、メンバーの会社ビジョンやミッションへの共感度がとても高い。正直今まで所属していた会社のビジョンやミッションはそこまで意識して働いていたことはなかったのですしそういった方を見たことなかったのですが、今の会社は全然違う。若い方も自分が何をしたいのかを明確に見てそれにあった会社を選んでいるので、方針等を決める際には会社のビジョンやミッションの話が必ずでてそれに沿って話が進んでいく。勿論、お金や数値の話は必要ですしそういう話もしますが、会社として事業としてどのように進んでいくのかの際にはビジョンやミッションに沿っているかが検討されているのは衝撃でした。「Xだと売り上げは上がるがミッションに沿っていないので、そういう方向性は考え直そう」みたいな。
そんな中、私自身はビジョンやミッションに共感したから入社したわけではない。社会貢献という軸で見てもボランティア経験は少しはあります*1が、考えたことすらない人生です。そもそも自分の考えとしては自分が基準なんですよね。パートナーや子もいますが、自分が楽しいからやる。子を可愛がったら子が喜んで私が嬉しいのでやる。みたいな。勿論、1年ほど働いた今となっては回りまわって自分に返ってきて自分が楽しい、嬉しい。というのはありますが、正直よくわからない。
が、そういった興味のない方をどうやって取り込んでいくのか。っというところは、当事者である私のような人じゃないとわからないと思うので、そういったところで戦力になれるかなと思っており、将来的にはその辺りを目標にして動いていけたら良いなと考えています。寄付とかしたことない人に如何に興味を持ってもらうのか面白そうじゃない。
エンジニアリングチームのリーダー
長くIT業界にいますが、実は開発チームのリーダーは初の経験。*2
とはいっても、ロードマップやスプリント等のタスク管理、サービス自体の品質は経験があったので特に問題はなかったはず。目指すことができたかというとそうではないですが、目指すところに近づくような動きはできたと思います。(多分)しかし、メンバーマネジメントに関しては難しい!メンバーのモチベーション向上や今後のキャリア等々。自分自身の経験に基づいたことは話すことができますが、当然人はそれぞれ違うのでそれを考慮するというのがとても難しい。私自身はあまり人の気持ちがわからないので気持ちを読み取ろうとするのではなく、信頼関係を気づいた上でなるべく話してもらうことを目指していきたいなと思っています。
なんでも話してもらうということを意識しているけれど、なんでも言える環境、関係を作るという部分が足りていなかったかなというのは、結構思うところがあります。また、最初はリーダーとして指名されたこと、周りからどう見えるかを意識しなさすぎた点、その後は逆にリーダーとして無理に振舞おうとしたという部分もあるので、自分は自分のままでやるべきことをやるということを意識していくというのも課題です
まぁまぁうまくやれたとは思いますが課題は色々出たので2024年はより良い形で終われるようにしていきたいです。
関係があった方の成長
2023年は前職等で付き合いがあった若い方がそれぞれ花開いていてとても嬉しい1年でした。転職を成功させた方、サービスを開発運用された方、フリーランスとして再開したら見違えるほど強くなっていた方など。自分でいうのもなんですが、大なり小なり影響を与えられたかなという方々なので成功してくれてたのはとても嬉しいです!来年以降も嬉しい話を聞きたいですね。
今年はフリーランスの方と一緒に働くことができたので、来年はもう1人でも一緒に働く機会を作れたらよいなと。
本読んだ
私は全然本を読まない、読めない人なのだけど今年は結構読んだ。とてもえらい。そもそもなんで読んだかというと、基礎ができていないという自覚があるので体系的に学びたいということと、よい年齢になってきたこともあって意識して勉強をしていかないとダメだよねーという思いから。↓にまとめてみたら14冊読んだらしい。技術書典産の薄い本が5冊もあるのでかさ増ししている感はあるけども素晴らしいと思う。読めたコツとしては出勤中の電車の中では必ず本を読むということ。大事な点は5分でも良いことと、帰りの電車は含まないところ。少しでもハードルは低くことが私にとっては継続していくコツなのだと思う。並べた本を見てみると、技術書典楽しかったなという思いが強い。今年も行く予定なので興味ある人は声かけて欲しいです。一緒に行きましょうー!
読んだ本
- 超・箇条書き―――「10倍速く、魅力的に」伝える技術
- https://www.amazon.co.jp/dp/4478068674
- 3/26 - 3/31
- 感想とかはXのスレッドで
周りに勧められた本が届いた。ちゃんと読むぞちゃんと読むぞちゃんと読むぞ。 pic.twitter.com/ZEfleJCI2n
— 山p☀ (@yamap_55) 2023年3月26日
- OKR(オーケーアール) シリコンバレー式で大胆な目標を達成する方法
- https://www.amazon.co.jp/dp/4822255646
- 4/17 - 5/7
- 感想とかはXのスレッドで
OKRを読むよ。https://t.co/IqmKjW7k54
— 山p☀ (@yamap_55) 2023年4月17日
- スタッフエンジニア マネジメントを超えるリーダーシップ
- https://www.amazon.co.jp/dp/429607055X
- 5/8 - 8/16
- 感想とかはXのスレッドで
読み始める。https://t.co/xDVC2HtQCV
— 山p☀ (@yamap_55) 2023年5月7日今日から、朝に本を読むこととした。
— 山p☀ (@yamap_55) 2023年8月2日
出社時は電車で読む。
「読む」とは5ページ以上とする。
- UIデザインの教科書[新版] マルチデバイス時代のインターフェース設計
- https://www.amazon.co.jp/dp/4798155454
- 8/17 - 8/25
- 感想とかはXのスレッドで
UIデザインの教科書読む。 pic.twitter.com/dK2ZROpNQI
— 山p☀ (@yamap_55) 2023年8月17日
- システム設計の面接試験
- https://www.amazon.co.jp/dp/4802614063
- 8/26 - 9/26
- 感想とかはXのスレッドで
システム設計の面接試験を読むよ。あまり悩まずにとりあえずサクッと読むことを心がけます。 pic.twitter.com/r43cP8vY8x
— 山p☀ (@yamap_55) 2023年8月26日
- 急成長を導くマネージャーの型 ~地位・権力が通用しない時代の“イーブン"なマネジメント
- https://www.amazon.co.jp/dp/4297123851
- 9/13 - 9/19
- 感想とかはXのスレッドで
「急成長を導くマネージャーの型」を読むよ
— 山p☀ (@yamap_55) 2023年9月13日
都合により来週までに読まないとなのでサクサク読む予定。 #読書 pic.twitter.com/Np7CWTfz9x
- 成果を生み出すテクニカルライティング ── トップエンジニア・研究者が実践する思考整理法
- https://www.amazon.co.jp/dp/4297104067
- 9/27 - 10/18
- 感想とかはXのスレッドで
#読書 今日から以前ポチってた「成果を生み出すテクニカルライティング」を読むよ pic.twitter.com/YoVnqr7Nou
— 山p☀ (@yamap_55) 2023年9月26日
- 副業で世界を変える方法 週末でアフリカに学校や貯水タンクを建設した会社員の物語
- https://www.amazon.co.jp/dp/B0CKZBG8Q4
- 10/14
- 感想とかはXのスレッドで
読んだ。私とは異なる生き方、選択をしていて単純に凄く面白かった。本を1日で読み切るとか久しぶりな気がする。社会貢献とか興味ある人は勿論、そうでなくても一人の人生として楽しめるのでオススメ。
— 山p☀ (@yamap_55) 2023年10月14日
私も壁があったら乗り越えないといかんなーっと思った次第です。https://t.co/fVaLIdeV9g
- こころの対話 25のルール
- https://www.amazon.co.jp/dp/4062564599
- 10/22 - 11/12
- 感想とかはXのスレッドで
#読書 明日から会社で薦められた「こころの対話25のルール」を読むよ。https://t.co/bKJf7SZlWd pic.twitter.com/vQXX6RoRL0
— 山p☀ (@yamap_55) 2023年10月22日
- データブリックス テックブック 〜2023年 秋〜
- https://techbookfest.org/product/3CwPbf0CLinrdHPiGfcbnH
- 11/13 - 11/17
- 感想とかはXのスレッドで
#読書 明日からは技術書典で購入したデータブリックステックブックを読むよ。https://t.co/yuWV6Z2ZxA
— 山p☀ (@yamap_55) 2023年11月12日
- OAuth、OAuth認証、OpenID Connectの違いを整理して理解できる本
- https://techbookfest.org/product/4885634867003392
- 11/20 - 11/29
- 感想とかはXのスレッドで
#読書 今日から技術書典で購入した「OAuth、OAuth認証、OpenID Connectの違いを整理して理解できる本」を読むよ。 pic.twitter.com/hqDODgIRM7
— 山p☀ (@yamap_55) 2023年11月19日
- 子連れキャリア旅行記
- https://techbookfest.org/product/dAmAYJwyDjWX3juiSbhVdt
- 12/1 - 12/6
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「子連れキャリア旅行記」を読むよ。 pic.twitter.com/0xeBQRJqHz
— 山p☀ (@yamap_55) 2023年11月30日
- マイクリプトヒーローズ解体新書虎の巻
- https://techbookfest.org/product/p4K5aVskhLCY3nh3dKe5sX
- 12/7 - 12/15
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「マイクリプトヒーローズ解体新書虎の巻」を読むよ。 pic.twitter.com/C1UrBKBuqN
— 山p☀ (@yamap_55) 2023年12月7日
- ChatGPTアプリを作って学ぶReact
- https://techbookfest.org/product/qJcZv2Lqr8nkjSsW3DxNrD
- 12/18 - 12/20
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「ChatGPTアプリを作って学ぶReact」を読むよ。 pic.twitter.com/4OexKBTcJk
— 山p☀ (@yamap_55) 2023年12月17日
今後のキャリア
年齢的にも経験的にもベテランと呼ばれる時期になってきて、直近は転職もあり目の前のことをこなすことが多くなると思っていたものの、今後のキャリアについてどうするかなとは思っていました。そういった時に出会ったのがスタッフエンジニア です。私の動きや目指すところがまさにスタッフエンジニアで、将来目指すところが明確になりました。また、名前が付いたことで他のケースを探すことができ、自分に何が足りないのか、どのような動きを行うべきなのかという先行事例、キャリアケースを探すことができることになったのも嬉しいです。私はスタッフエンジニアの4つの原形の中でも右腕の役割を担いつつ、他の役割をこなしていくという感じですかね。具体的にはCTOを補佐しつつ会社全体としてエンジニア組織を作り、非エンジニアに対してもサポートしていくような形で動いていくことを考えています。
勿論、これは今の段階の話であり変わることは十分ありますが、たとえ一時でも人生でキャリアについてはっきりと決まった瞬間というのはなかったのでこれは大きな転機であるはずです。2024年も頑張るぞ!
最後に
まとめると2023年は転機もあり大きく飛躍できた1年だったなという感想です。明らかに考え方や方向性が良い方向に変わっていますし成長を感じます。2024年も同様かそれ以上の感想を抱けるように、「こんな振り返りしてるけど勘違いだったわwww」っとならないように、日々頑張っていきましょー
転職したよ
はじめにの前に
- 本記事は2022年末に書いて、2023/03くらいに公開する予定だったけど完全に忘れていた記事です。
- 夏くらいに気づいたけどまぁいいかと思って放置してたけど、せっかくなので今(2023/12/31)公開してみます。
- 公開時点では現職(この記事でいうところの転職先)に1年いるわけですが、その話はないです。
はじめに(概要)
- 株式会社ALBERT の最終出社が2022/12/20
- 2017/07/01から2023/03まで所属。有給休暇の残が多かったので実質5年5か月くらい(以下5年半と記載)
- 今はアクセンチュアに取り込まれたので存在しない
- データ分析とかAIとかそういうことやっていた
- 私の職種はエンジニア
- 転職先は 株式会社STYZ
- 2023/01から所属
- 非営利団体向けの寄付フォーム開発とかしている
- 私の職種はエンジニア -> エンジニアチームのリーダー
- 前回の転職は↓
- 本記事は5年半間の振り返り、成長記録を書いたポエム
やってたこと
- 全体で5年半のうち、社内案件1年半、常駐4年でほとんど常駐
- マネージャ業務はほぼなし。1エンジニアとして設計して、コード書いていた
- 厳密にいうとメンバの管理業務はあるにはあったが、同チームどころか部署も違うし職種も違うので建前的な奴。
- 詳細も書いたけど長くなったので下のほうに移動した
エンジニアとしての自信
前回の転職時には 私はそれなりにコード書けるという自信 としていましたが、これは中堅エンジニアとしてやっていけるかな。くらいの自信でした。ただ、今はシニアエンジニアとして自称できるくらいの自信は持っています。 狭義のエンジニアとしてみると技術面が強く出ると思うため良くて1.5流かなと思いますが、技術面以外の部分でエンジニアとしての自信を持つことができました。具体的には他者の教育(特にエンジニア以外)であったり、エンジニア文化*1の創出や向上、エンジニア職種以外の方へのエンジニアリング技術の啓蒙やエンジニアの使い方(扱い方)、一緒に働くことのメリットを伝えることのように、組織へ貢献することができるようになりました。っというか、これ自体がエンジニアとしての価値になるということがわかったということが成長かなと思っているところです。
やりたいことをやる
先日の記事にも書きましたが、自分のやりたいことをやるということをできるようになりました。こう書くとちょっと響きが良くないですが、言われたことをやるだけではなく仕事を作り出すことで自分のやりたいことをやる。組織は基本的に利益がでれば良いので、自分がやりたいことを提案する際に組織に利益となるということを主張すればよい。言い出しっぺが大なり小なり絡むことになるのでやりたいことができると。また、利益になることを提案したとして評価されるところもポイント。自分のやりたいことと組織が向いている方向*2が同一である前提ではありますが、そもそもそれが異なっていたらその組織にいる必要はないという話。私自身は世界を変えるような大きいことをしたいということはないため少しの働き方でやりたいことができるというのもあります。視座が上がることで難しくなるのかもしれませんが、その時は別の動き方もあるのかなと思っております。とりあえず、動き方が変わってきたというのがポイント。
人に教える
これも前回の転職時にも書いたことですが、私は人に教えることが好きで適性がありそうです。純エンジニアとはほぼ仕事をしていなかったのですが、逆にエンジニア以外の職種の人とエンジニアリングの仕事をする機会は多数ありました。そのほぼ全てで一緒に働く機会が持ててよかったという評価を頂いたのは自信となりました。結果的に道場長や先生という肩書?で呼ばれるようになったのも恥ずかしいですが嬉しいことでした。*3
※以前の転職の時にエンジニアの講師として声をかけていただいたのですが、そちらの道でもまあまあうまくやれたのかもしれない
まとめ
飛躍的に伸びた5年半でした。反省点はありつつも大きな失敗もなく貴重な経験を得ました。また、多数の人と繋がりが持てたことも重要です。*4割と今までの会社では仲は良かったものの次(?)に繋がるという形ではなかなかいかなかったのですが、今回は開発メンバーという以上に関われた方が多くいたためよりよい関係を築けていけそうです。 今後も山pの活躍にご期待ください!
やってたこと詳細
社内案件内訳(時期に被りあり)
- プライベートDMP(Data Management Platform)開発、保守(3カ月)
- 入社直後に慣れるまでとりあえずエンジニアとして入った感じ
- システムの作り自体はそれほど得るものはなかったが5年間の基本となるデータ分析の基礎となる情報を色々学べた
- 作りが悪いと言っているわけではない
- データの持ち方、バッチシステムの作り方、通常?のよくあるシステムとデータ分析系のシステムとの違いとか
- 社員のエンジニアと働いたのはこれが最初で最後
- ここだけ切り取ると酷い境遇だったように見える(そんなことは思ってないです)
- プライベートDMP導入企業のPM(6カ月)
- アサインされてすぐにPMが体調不良で抜けたことによる交代だったのでかなり焦った
- 既に導入から数年経っていて最終的に企業側で自前?で作ったものに移行してClose
- クライアントと話して色々やるのは経験になった
- 入った時からCloseが見えていたので色々目こぼししてもらいつつも、過去の遺産を漁る作業が多かった記憶
- Close作業は多分初で、色々面倒なことあるなーと思った記憶あり
- 割と大きいクライアントだったので普段は温厚でもいきなり圧が凄いときがあった
- 分析案件PM(9カ月)
- 定型レポートの提出的なお使い業務と聞いていたのに、実際に会ってみたら分析についてサポートしろよと言われて、えーってなった案件
- やれることはやっていたという自負はあるが、そもそも分析者ではないので最終的には担当者交代となった
- 信頼関係はできていたと思うので完全に実力不足というか、私をアサインしたのが悪いと言いたい
- 上司への相談、アラート上げるのが遅かったという反省は強くある
- 学習モデルPOCからのシステム開発案件PM(3カ月)
- 大変という言葉でしかない
- 新規で作っている大きなシステム内で使われる1機能、APIみたいなイメージ
- POCで作った学習モデルを組み込んで予測するという話が、クライアント的には学習モデルを作るという話になってて笑った
- 上位の大きなシステム作っているベンダーに界隈の有名人がいてその人もクライアントに振り回されていた
- 今から考えるとなんであんな案件をうちでやっていたのだろうか。最初はPOCだけやるつもりだったのに上位のベンダーが無理って言ったのか?
- 何もわかっていないのに承認するんだなーっと、要件定義の難しさを知った
- とりあえず期間が短すぎて最低限のことしかできなかったけど、1つのシステムを作り上げたという自信には繋がった
- 学習モデルPOCからのシステム開発案件PM(2カ月)
- これも大変だった
- POC段階でほぼシステム的に動くものはあるからと2カ月になっていたが。。。
- データサイエンティストとエンジニアとの違いを実感した案件
- 確かに動くものはある
- POCとして条件が色々ある状態のものであり正常系のみ
- 細かい部分も考慮されていないので結局仕様を読みつつ再実装が必要
- 学習モデルやAIを使用するPOCからのシステム化案件をこの後も色々見たけど、全てのアンチパターンを踏み抜いていた案件だった
- 他にも細かい案件いくつか
- 月5万の保守案件
- 遥か昔の案件システムの極々一部の保守
- クライアントもこちらも誰も仕様を知らない
- クライアント側に手動作業があるのだが催促してもやってくれない(多分使っていない)
- 更に値切られたときにはなんで案件切らないのかクライアント、社内ともに問い詰めた
- 月5万の保守案件