転職して1年経ったまとめと2023年の振り返り

はじめに
この記事は2023年の振り返りをすることで2024年に気合を入れようという記事、ポエムです。40代のITエンジニアがどういうこと考えて日々を過ごしているのかは少しわかるかも。ITエンジニアチックな話は少なめです。
何日かに分けて書いていたら7000文字弱という文字数になってしまった。それだけ盛り盛りの1年だったということで良いことです。
ベンチャー企業への転職
2023年の1月から株式会社STYZへ転職しました。Syncable という非営利組織向けの寄付プラットフォームサービスを開発しています。創業8年目で40人くらいの会社です。メンバーの全体的に若く、経営陣含めても私が最年長です。転職したきっかけは一緒に働きたいと思っていた人に誘われたため。
今までの所属企業も大企業(従業員1000人以上)のみいうことではなかったですが、最低でも100人以上所属 OR 大企業の子会社だったので会社内部制度等の会社としてあるべきこと?は大体揃っていて運用されているっという状態でした。これも振り返ってみればそう思うというだけで、当時はそんなこと考えてもみなかった。
で、転職してみたらあって当たり前、やってくれて当たり前と思っていたことが多いこと多いこと。これはITエンジニアとして、開発業務は勿論。会社の制度やオフィスそのもの、物品、会社として?社員として?みたいなことなどなど様々です。具体的に書けることはあまりないのですが、誰かがやってくれてたんだなということがとても多く、自分でやらなければならないこと、やり方が決まっていないこと、誰もやっていないこと、そもそもモノがない。そんなことばかり。
ただ、話を聞くと、チーム、会社としては必要。誰かがやらなければならない。やり方を決めなければならないという。っという意識はあるが手が回っていないという状況です。これらを率先して拾っていくことで、経営陣、若い方、中堅、ベテランの方問わずにこいつなんか色々やってくれるぞ?っと思われて信頼貯金の形成に大きく役立ったと思います。拾い方としても「XX探してもみつからないのですがありますか?ないならとりあえず決めちゃうのでレビューお願いします。」みたいな感じでさっさと動いちゃうと、自分のやりやすい形、慣れている形で決めることができるのでとても楽でした。上位者が気になる点あれば後で突っ込んでくれますし。(突っ込みなかったら全体に展開するだけ)
そしてこういう動きをしているとやたら褒められる!!今の会社で一番好きなのはみんな褒めてくれるとこです。大好きです。この文章を書きながら、私はこんなに褒めてもらって喜んでいるのに、皆を褒めているのか?と気づいてしまったので、2024年は良いところ、嬉しかったことは褒めていくことを心がけていきます。
メンバーの会社への共感度
会社のビジョンは「あらゆる境遇を打破できる社会」、ミッションは「民間から多種多様な社会保障を行き渡らせる」というものです。若い会社だからか事業が社会貢献性が高いからなのかはわかりませんが、メンバーの会社ビジョンやミッションへの共感度がとても高い。正直今まで所属していた会社のビジョンやミッションはそこまで意識して働いていたことはなかったのですしそういった方を見たことなかったのですが、今の会社は全然違う。若い方も自分が何をしたいのかを明確に見てそれにあった会社を選んでいるので、方針等を決める際には会社のビジョンやミッションの話が必ずでてそれに沿って話が進んでいく。勿論、お金や数値の話は必要ですしそういう話もしますが、会社として事業としてどのように進んでいくのかの際にはビジョンやミッションに沿っているかが検討されているのは衝撃でした。「Xだと売り上げは上がるがミッションに沿っていないので、そういう方向性は考え直そう」みたいな。
そんな中、私自身はビジョンやミッションに共感したから入社したわけではない。社会貢献という軸で見てもボランティア経験は少しはあります*1が、考えたことすらない人生です。そもそも自分の考えとしては自分が基準なんですよね。パートナーや子もいますが、自分が楽しいからやる。子を可愛がったら子が喜んで私が嬉しいのでやる。みたいな。勿論、1年ほど働いた今となっては回りまわって自分に返ってきて自分が楽しい、嬉しい。というのはありますが、正直よくわからない。
が、そういった興味のない方をどうやって取り込んでいくのか。っというところは、当事者である私のような人じゃないとわからないと思うので、そういったところで戦力になれるかなと思っており、将来的にはその辺りを目標にして動いていけたら良いなと考えています。寄付とかしたことない人に如何に興味を持ってもらうのか面白そうじゃない。
エンジニアリングチームのリーダー
長くIT業界にいますが、実は開発チームのリーダーは初の経験。*2
とはいっても、ロードマップやスプリント等のタスク管理、サービス自体の品質は経験があったので特に問題はなかったはず。目指すことができたかというとそうではないですが、目指すところに近づくような動きはできたと思います。(多分)しかし、メンバーマネジメントに関しては難しい!メンバーのモチベーション向上や今後のキャリア等々。自分自身の経験に基づいたことは話すことができますが、当然人はそれぞれ違うのでそれを考慮するというのがとても難しい。私自身はあまり人の気持ちがわからないので気持ちを読み取ろうとするのではなく、信頼関係を気づいた上でなるべく話してもらうことを目指していきたいなと思っています。
なんでも話してもらうということを意識しているけれど、なんでも言える環境、関係を作るという部分が足りていなかったかなというのは、結構思うところがあります。また、最初はリーダーとして指名されたこと、周りからどう見えるかを意識しなさすぎた点、その後は逆にリーダーとして無理に振舞おうとしたという部分もあるので、自分は自分のままでやるべきことをやるということを意識していくというのも課題です
まぁまぁうまくやれたとは思いますが課題は色々出たので2024年はより良い形で終われるようにしていきたいです。
関係があった方の成長
2023年は前職等で付き合いがあった若い方がそれぞれ花開いていてとても嬉しい1年でした。転職を成功させた方、サービスを開発運用された方、フリーランスとして再開したら見違えるほど強くなっていた方など。自分でいうのもなんですが、大なり小なり影響を与えられたかなという方々なので成功してくれてたのはとても嬉しいです!来年以降も嬉しい話を聞きたいですね。
今年はフリーランスの方と一緒に働くことができたので、来年はもう1人でも一緒に働く機会を作れたらよいなと。
本読んだ
私は全然本を読まない、読めない人なのだけど今年は結構読んだ。とてもえらい。そもそもなんで読んだかというと、基礎ができていないという自覚があるので体系的に学びたいということと、よい年齢になってきたこともあって意識して勉強をしていかないとダメだよねーという思いから。↓にまとめてみたら14冊読んだらしい。技術書典産の薄い本が5冊もあるのでかさ増ししている感はあるけども素晴らしいと思う。読めたコツとしては出勤中の電車の中では必ず本を読むということ。大事な点は5分でも良いことと、帰りの電車は含まないところ。少しでもハードルは低くことが私にとっては継続していくコツなのだと思う。並べた本を見てみると、技術書典楽しかったなという思いが強い。今年も行く予定なので興味ある人は声かけて欲しいです。一緒に行きましょうー!
読んだ本
- 超・箇条書き―――「10倍速く、魅力的に」伝える技術
- https://www.amazon.co.jp/dp/4478068674
- 3/26 - 3/31
- 感想とかはXのスレッドで
周りに勧められた本が届いた。ちゃんと読むぞちゃんと読むぞちゃんと読むぞ。 pic.twitter.com/ZEfleJCI2n
— 山p☀ (@yamap_55) 2023年3月26日
- OKR(オーケーアール) シリコンバレー式で大胆な目標を達成する方法
- https://www.amazon.co.jp/dp/4822255646
- 4/17 - 5/7
- 感想とかはXのスレッドで
OKRを読むよ。https://t.co/IqmKjW7k54
— 山p☀ (@yamap_55) 2023年4月17日
- スタッフエンジニア マネジメントを超えるリーダーシップ
- https://www.amazon.co.jp/dp/429607055X
- 5/8 - 8/16
- 感想とかはXのスレッドで
読み始める。https://t.co/xDVC2HtQCV
— 山p☀ (@yamap_55) 2023年5月7日今日から、朝に本を読むこととした。
— 山p☀ (@yamap_55) 2023年8月2日
出社時は電車で読む。
「読む」とは5ページ以上とする。
- UIデザインの教科書[新版] マルチデバイス時代のインターフェース設計
- https://www.amazon.co.jp/dp/4798155454
- 8/17 - 8/25
- 感想とかはXのスレッドで
UIデザインの教科書読む。 pic.twitter.com/dK2ZROpNQI
— 山p☀ (@yamap_55) 2023年8月17日
- システム設計の面接試験
- https://www.amazon.co.jp/dp/4802614063
- 8/26 - 9/26
- 感想とかはXのスレッドで
システム設計の面接試験を読むよ。あまり悩まずにとりあえずサクッと読むことを心がけます。 pic.twitter.com/r43cP8vY8x
— 山p☀ (@yamap_55) 2023年8月26日
- 急成長を導くマネージャーの型 ~地位・権力が通用しない時代の“イーブン"なマネジメント
- https://www.amazon.co.jp/dp/4297123851
- 9/13 - 9/19
- 感想とかはXのスレッドで
「急成長を導くマネージャーの型」を読むよ
— 山p☀ (@yamap_55) 2023年9月13日
都合により来週までに読まないとなのでサクサク読む予定。 #読書 pic.twitter.com/Np7CWTfz9x
- 成果を生み出すテクニカルライティング ── トップエンジニア・研究者が実践する思考整理法
- https://www.amazon.co.jp/dp/4297104067
- 9/27 - 10/18
- 感想とかはXのスレッドで
#読書 今日から以前ポチってた「成果を生み出すテクニカルライティング」を読むよ pic.twitter.com/YoVnqr7Nou
— 山p☀ (@yamap_55) 2023年9月26日
- 副業で世界を変える方法 週末でアフリカに学校や貯水タンクを建設した会社員の物語
- https://www.amazon.co.jp/dp/B0CKZBG8Q4
- 10/14
- 感想とかはXのスレッドで
読んだ。私とは異なる生き方、選択をしていて単純に凄く面白かった。本を1日で読み切るとか久しぶりな気がする。社会貢献とか興味ある人は勿論、そうでなくても一人の人生として楽しめるのでオススメ。
— 山p☀ (@yamap_55) 2023年10月14日
私も壁があったら乗り越えないといかんなーっと思った次第です。https://t.co/fVaLIdeV9g
- こころの対話 25のルール
- https://www.amazon.co.jp/dp/4062564599
- 10/22 - 11/12
- 感想とかはXのスレッドで
#読書 明日から会社で薦められた「こころの対話25のルール」を読むよ。https://t.co/bKJf7SZlWd pic.twitter.com/vQXX6RoRL0
— 山p☀ (@yamap_55) 2023年10月22日
- データブリックス テックブック 〜2023年 秋〜
- https://techbookfest.org/product/3CwPbf0CLinrdHPiGfcbnH
- 11/13 - 11/17
- 感想とかはXのスレッドで
#読書 明日からは技術書典で購入したデータブリックステックブックを読むよ。https://t.co/yuWV6Z2ZxA
— 山p☀ (@yamap_55) 2023年11月12日
- OAuth、OAuth認証、OpenID Connectの違いを整理して理解できる本
- https://techbookfest.org/product/4885634867003392
- 11/20 - 11/29
- 感想とかはXのスレッドで
#読書 今日から技術書典で購入した「OAuth、OAuth認証、OpenID Connectの違いを整理して理解できる本」を読むよ。 pic.twitter.com/hqDODgIRM7
— 山p☀ (@yamap_55) 2023年11月19日
- 子連れキャリア旅行記
- https://techbookfest.org/product/dAmAYJwyDjWX3juiSbhVdt
- 12/1 - 12/6
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「子連れキャリア旅行記」を読むよ。 pic.twitter.com/0xeBQRJqHz
— 山p☀ (@yamap_55) 2023年11月30日
- マイクリプトヒーローズ解体新書虎の巻
- https://techbookfest.org/product/p4K5aVskhLCY3nh3dKe5sX
- 12/7 - 12/15
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「マイクリプトヒーローズ解体新書虎の巻」を読むよ。 pic.twitter.com/C1UrBKBuqN
— 山p☀ (@yamap_55) 2023年12月7日
- ChatGPTアプリを作って学ぶReact
- https://techbookfest.org/product/qJcZv2Lqr8nkjSsW3DxNrD
- 12/18 - 12/20
- 感想とかはXのスレッドで
#読書 明日から技術書典で購入した「ChatGPTアプリを作って学ぶReact」を読むよ。 pic.twitter.com/4OexKBTcJk
— 山p☀ (@yamap_55) 2023年12月17日
今後のキャリア
年齢的にも経験的にもベテランと呼ばれる時期になってきて、直近は転職もあり目の前のことをこなすことが多くなると思っていたものの、今後のキャリアについてどうするかなとは思っていました。そういった時に出会ったのがスタッフエンジニア です。私の動きや目指すところがまさにスタッフエンジニアで、将来目指すところが明確になりました。また、名前が付いたことで他のケースを探すことができ、自分に何が足りないのか、どのような動きを行うべきなのかという先行事例、キャリアケースを探すことができることになったのも嬉しいです。私はスタッフエンジニアの4つの原形の中でも右腕の役割を担いつつ、他の役割をこなしていくという感じですかね。具体的にはCTOを補佐しつつ会社全体としてエンジニア組織を作り、非エンジニアに対してもサポートしていくような形で動いていくことを考えています。
勿論、これは今の段階の話であり変わることは十分ありますが、たとえ一時でも人生でキャリアについてはっきりと決まった瞬間というのはなかったのでこれは大きな転機であるはずです。2024年も頑張るぞ!
最後に
まとめると2023年は転機もあり大きく飛躍できた1年だったなという感想です。明らかに考え方や方向性が良い方向に変わっていますし成長を感じます。2024年も同様かそれ以上の感想を抱けるように、「こんな振り返りしてるけど勘違いだったわwww」っとならないように、日々頑張っていきましょー
転職したよ
はじめにの前に
- 本記事は2022年末に書いて、2023/03くらいに公開する予定だったけど完全に忘れていた記事です。
- 夏くらいに気づいたけどまぁいいかと思って放置してたけど、せっかくなので今(2023/12/31)公開してみます。
- 公開時点では現職(この記事でいうところの転職先)に1年いるわけですが、その話はないです。
はじめに(概要)
- 株式会社ALBERT の最終出社が2022/12/20
- 2017/07/01から2023/03まで所属。有給休暇の残が多かったので実質5年5か月くらい(以下5年半と記載)
- 今はアクセンチュアに取り込まれたので存在しない
- データ分析とかAIとかそういうことやっていた
- 私の職種はエンジニア
- 転職先は 株式会社STYZ
- 2023/01から所属
- 非営利団体向けの寄付フォーム開発とかしている
- 私の職種はエンジニア -> エンジニアチームのリーダー
- 前回の転職は↓
- 本記事は5年半間の振り返り、成長記録を書いたポエム
やってたこと
- 全体で5年半のうち、社内案件1年半、常駐4年でほとんど常駐
- マネージャ業務はほぼなし。1エンジニアとして設計して、コード書いていた
- 厳密にいうとメンバの管理業務はあるにはあったが、同チームどころか部署も違うし職種も違うので建前的な奴。
- 詳細も書いたけど長くなったので下のほうに移動した
エンジニアとしての自信
前回の転職時には 私はそれなりにコード書けるという自信 としていましたが、これは中堅エンジニアとしてやっていけるかな。くらいの自信でした。ただ、今はシニアエンジニアとして自称できるくらいの自信は持っています。 狭義のエンジニアとしてみると技術面が強く出ると思うため良くて1.5流かなと思いますが、技術面以外の部分でエンジニアとしての自信を持つことができました。具体的には他者の教育(特にエンジニア以外)であったり、エンジニア文化*1の創出や向上、エンジニア職種以外の方へのエンジニアリング技術の啓蒙やエンジニアの使い方(扱い方)、一緒に働くことのメリットを伝えることのように、組織へ貢献することができるようになりました。っというか、これ自体がエンジニアとしての価値になるということがわかったということが成長かなと思っているところです。
やりたいことをやる
先日の記事にも書きましたが、自分のやりたいことをやるということをできるようになりました。こう書くとちょっと響きが良くないですが、言われたことをやるだけではなく仕事を作り出すことで自分のやりたいことをやる。組織は基本的に利益がでれば良いので、自分がやりたいことを提案する際に組織に利益となるということを主張すればよい。言い出しっぺが大なり小なり絡むことになるのでやりたいことができると。また、利益になることを提案したとして評価されるところもポイント。自分のやりたいことと組織が向いている方向*2が同一である前提ではありますが、そもそもそれが異なっていたらその組織にいる必要はないという話。私自身は世界を変えるような大きいことをしたいということはないため少しの働き方でやりたいことができるというのもあります。視座が上がることで難しくなるのかもしれませんが、その時は別の動き方もあるのかなと思っております。とりあえず、動き方が変わってきたというのがポイント。
人に教える
これも前回の転職時にも書いたことですが、私は人に教えることが好きで適性がありそうです。純エンジニアとはほぼ仕事をしていなかったのですが、逆にエンジニア以外の職種の人とエンジニアリングの仕事をする機会は多数ありました。そのほぼ全てで一緒に働く機会が持ててよかったという評価を頂いたのは自信となりました。結果的に道場長や先生という肩書?で呼ばれるようになったのも恥ずかしいですが嬉しいことでした。*3
※以前の転職の時にエンジニアの講師として声をかけていただいたのですが、そちらの道でもまあまあうまくやれたのかもしれない
まとめ
飛躍的に伸びた5年半でした。反省点はありつつも大きな失敗もなく貴重な経験を得ました。また、多数の人と繋がりが持てたことも重要です。*4割と今までの会社では仲は良かったものの次(?)に繋がるという形ではなかなかいかなかったのですが、今回は開発メンバーという以上に関われた方が多くいたためよりよい関係を築けていけそうです。 今後も山pの活躍にご期待ください!
やってたこと詳細
社内案件内訳(時期に被りあり)
- プライベートDMP(Data Management Platform)開発、保守(3カ月)
- 入社直後に慣れるまでとりあえずエンジニアとして入った感じ
- システムの作り自体はそれほど得るものはなかったが5年間の基本となるデータ分析の基礎となる情報を色々学べた
- 作りが悪いと言っているわけではない
- データの持ち方、バッチシステムの作り方、通常?のよくあるシステムとデータ分析系のシステムとの違いとか
- 社員のエンジニアと働いたのはこれが最初で最後
- ここだけ切り取ると酷い境遇だったように見える(そんなことは思ってないです)
- プライベートDMP導入企業のPM(6カ月)
- アサインされてすぐにPMが体調不良で抜けたことによる交代だったのでかなり焦った
- 既に導入から数年経っていて最終的に企業側で自前?で作ったものに移行してClose
- クライアントと話して色々やるのは経験になった
- 入った時からCloseが見えていたので色々目こぼししてもらいつつも、過去の遺産を漁る作業が多かった記憶
- Close作業は多分初で、色々面倒なことあるなーと思った記憶あり
- 割と大きいクライアントだったので普段は温厚でもいきなり圧が凄いときがあった
- 分析案件PM(9カ月)
- 定型レポートの提出的なお使い業務と聞いていたのに、実際に会ってみたら分析についてサポートしろよと言われて、えーってなった案件
- やれることはやっていたという自負はあるが、そもそも分析者ではないので最終的には担当者交代となった
- 信頼関係はできていたと思うので完全に実力不足というか、私をアサインしたのが悪いと言いたい
- 上司への相談、アラート上げるのが遅かったという反省は強くある
- 学習モデルPOCからのシステム開発案件PM(3カ月)
- 大変という言葉でしかない
- 新規で作っている大きなシステム内で使われる1機能、APIみたいなイメージ
- POCで作った学習モデルを組み込んで予測するという話が、クライアント的には学習モデルを作るという話になってて笑った
- 上位の大きなシステム作っているベンダーに界隈の有名人がいてその人もクライアントに振り回されていた
- 今から考えるとなんであんな案件をうちでやっていたのだろうか。最初はPOCだけやるつもりだったのに上位のベンダーが無理って言ったのか?
- 何もわかっていないのに承認するんだなーっと、要件定義の難しさを知った
- とりあえず期間が短すぎて最低限のことしかできなかったけど、1つのシステムを作り上げたという自信には繋がった
- 学習モデルPOCからのシステム開発案件PM(2カ月)
- これも大変だった
- POC段階でほぼシステム的に動くものはあるからと2カ月になっていたが。。。
- データサイエンティストとエンジニアとの違いを実感した案件
- 確かに動くものはある
- POCとして条件が色々ある状態のものであり正常系のみ
- 細かい部分も考慮されていないので結局仕様を読みつつ再実装が必要
- 学習モデルやAIを使用するPOCからのシステム化案件をこの後も色々見たけど、全てのアンチパターンを踏み抜いていた案件だった
- 他にも細かい案件いくつか
- 月5万の保守案件
- 遥か昔の案件システムの極々一部の保守
- クライアントもこちらも誰も仕様を知らない
- クライアント側に手動作業があるのだが催促してもやってくれない(多分使っていない)
- 更に値切られたときにはなんで案件切らないのかクライアント、社内ともに問い詰めた
- 月5万の保守案件
常駐案件
【無料】Minecraft統合版サーバーをOracle Cloudで作成する
- はじめに
- 内容の難しさ
- コンパートメントの作成
- インスタンスの作成
- 固定IPを取得
- インスタンスのIPを固定
- インスタンスのポート開放
- インスタンスへのSSH接続
- インスタンスの設定
- Minecraftをインストール
- 起動設定
- Nintendo Switch から接続する
- 未成年アカウントで外部サーバーに接続する場合
- Minecraft設定
- バックアップについて
- Minecraftバージョンアップについて
- Minecraft のバックアップについて
はじめに
- Oracle Cloudは無料利用枠(Always Free)として他のCloudサービスと比べても比較的性能の良い仮想サーバーを提供しています
- 無料利用枠の中で、CPUがAMDの仮想サーバーを利用してMinecraft統合版のサーバを構築します
- CPUをArmにすることで4CPU、メモリ24GBという環境も無料で作成可能ですが、MinecraftがArmをサポートしていないため、通常の使用方法では動作しません
- 一応、方法はあるようなので参考の記事は示しておきます(私は試してみましたがダメでした)
- 【成功】マインクラフト統合版サーバ(Bedrock Dedicated Server)をOCIのArmプロセッサで動かしてみる-ピピローグ
- Official Minecraft Bedrock Dedicated Server on Raspberry Pi*
- 本手順はOracle Cloudのユーザー登録は完了していることを前提としていますので、ユーザー登録が行われていない方は「Oracle Cloud Free Tier Signup」辺りから作成してください
- 本記事執筆時の情報で記載していますので、実践する際には実際の画面やバージョン等を確認しながら行ってください
内容の難しさ
- なるべくわかるように書きますが、CloudサービスやLinuxの基礎操作ができないと作成するのは難しいです
- 便利設定などはコード書いたりするのでこの辺りも慣れていないと難しいと思われます
コンパートメントの作成
前置き
- コンパートメントとはリソースをグループ分けするようなものらしいです
- コンパートメントの管理
- 作成せずrootに配置しても動作は可能ですが、今後Oracle Cloudを別の用途で使用する場合に備えて作成しておきます
手順
- コンパートメントページを表示
- コンパートメントの作成ボタン押下
- 必要な情報を入力
- 名前: わかりやすい任意の名前(本記事では
minecraft_serverとしました) - 説明: わかりやすい任意の説明(本記事では
minecraft serverとしました) - 親コンパートメント: root
- タグ: 必要であれば設定
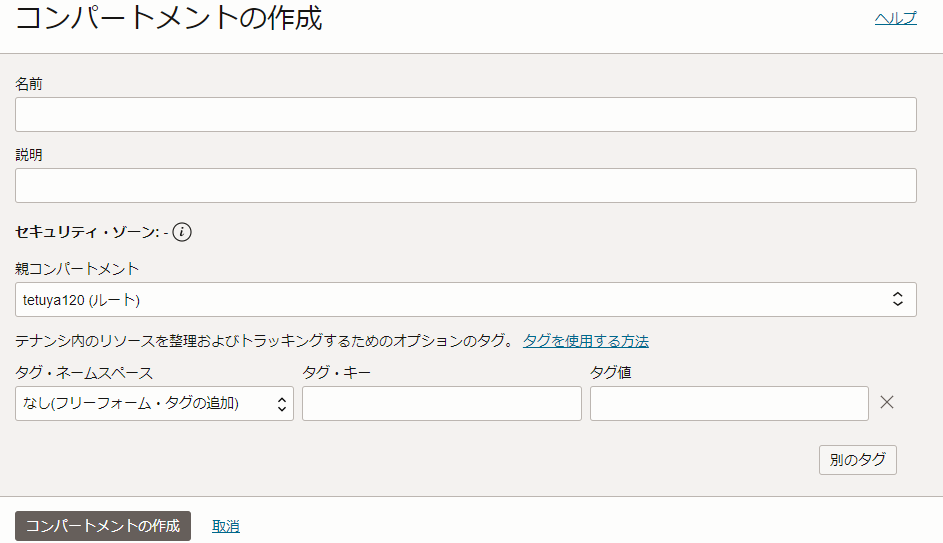
- 名前: わかりやすい任意の名前(本記事では
インスタンスの作成
前置き
手順
- インスタンスページを表示
- インスタンスの作成ボタン押下
- 必要情報を入力(その1)
- 名前: わかりやすい任意の名前(本記事では
minecraft_server_instance_testとしました) - コンパートメントに作成: ↑で作成したコンパートメントを選択
- 配置、セキュリティ: デフォルト
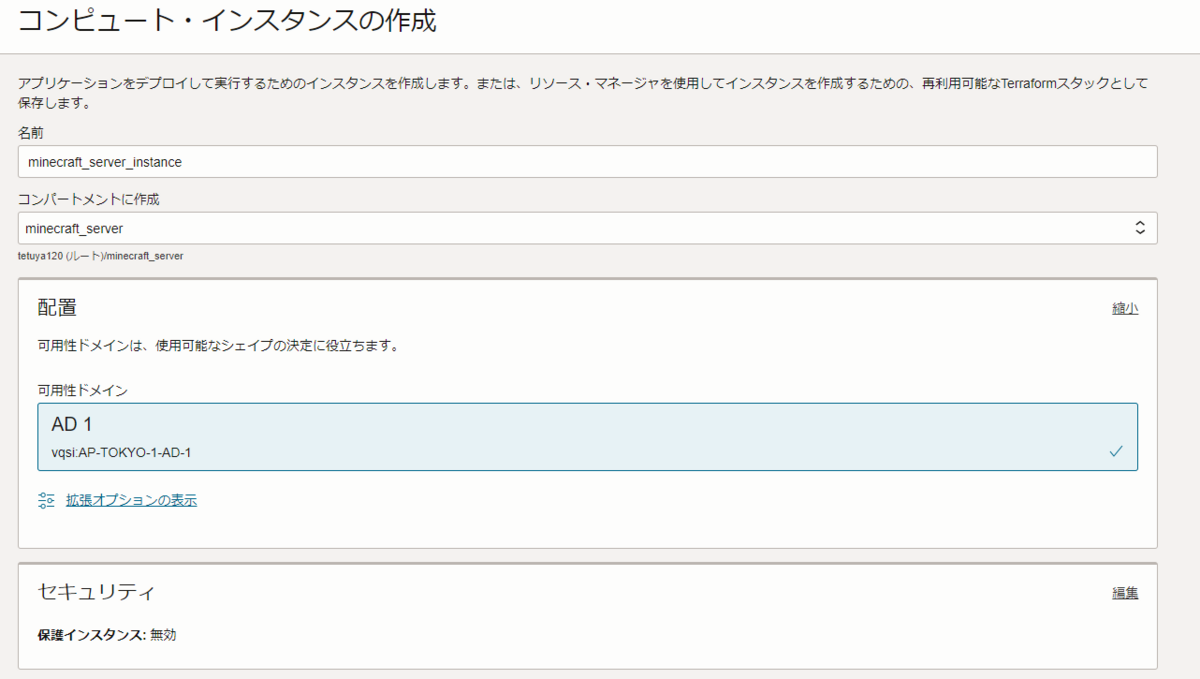
- 名前: わかりやすい任意の名前(本記事では
- イメージとシェイプ
- イメージ: Ubuntu22のMinimal(本記事では
Canonical Ubuntu 22.04 Minimalとしました) - シェイプ: VM.Standard.E2.1.Micro
- 「Always Free対象」となっていることを確認
- 「はじめに」に書いたが、AmpereにもAlways Free対象がありスペックは格段にこちらが高いが、ArmCPUで動作させるのは難しいです
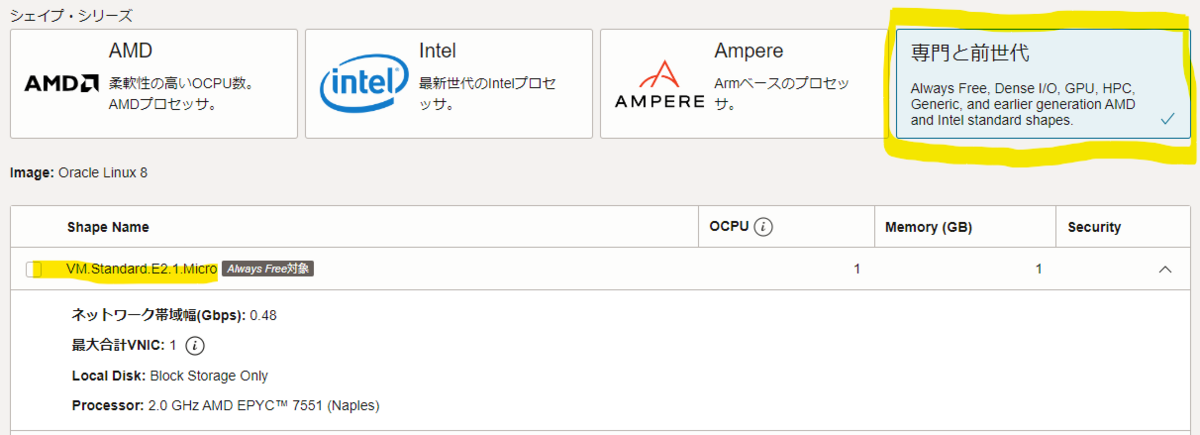

- イメージ: Ubuntu22のMinimal(本記事では
- 必要な情報を入力(その2)
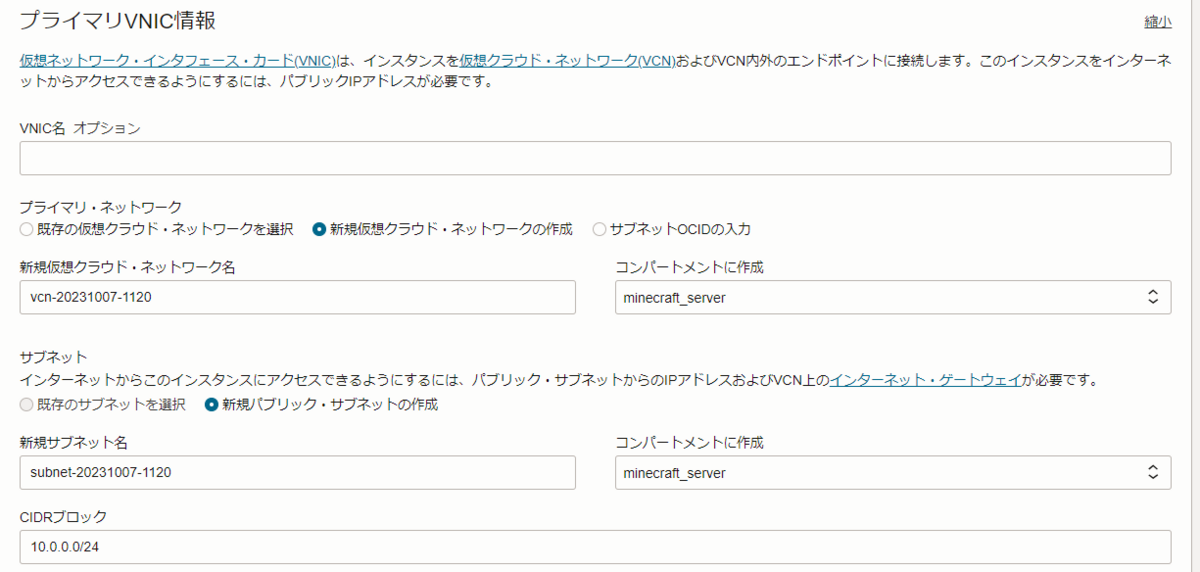
- プライマリVNIC IPアドレス、セカンダリVNICオプション
- デフォルトでOK
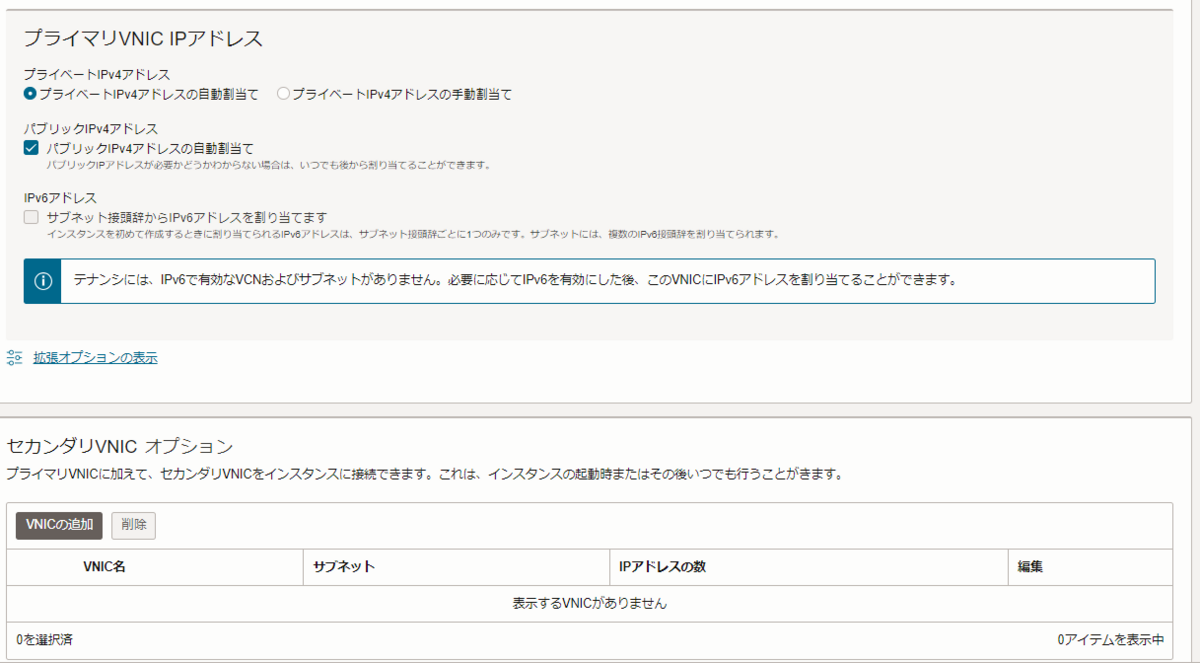
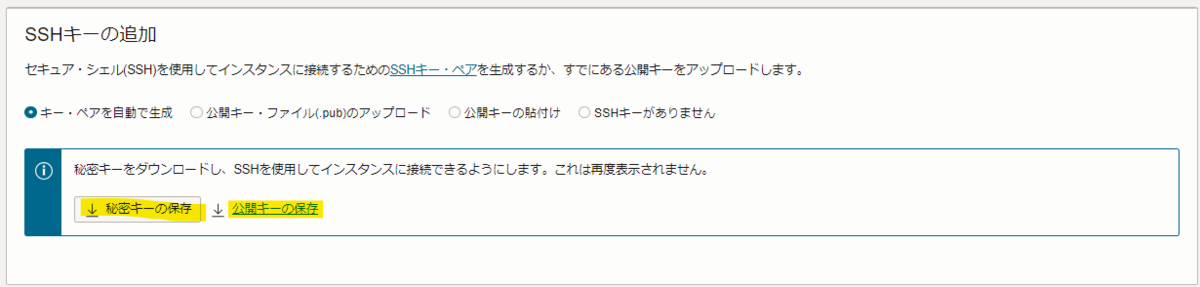
- SSHキーの追加
- キー・ペアを自動で生成を選択
- 使いたいキーがあるならば適当にしてください
- ※秘密キーの保存、公開キーの保存を忘れずに
- 忘れた場合には作成時に警告してくれます
- キー・ペアを自動で生成を選択
- ブート・ボリューム
- デフォルト
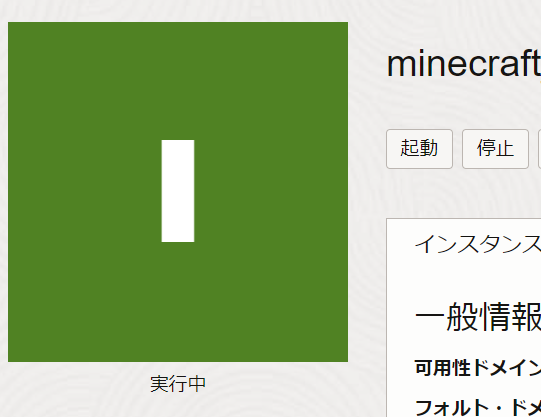
- 作成ボタン押下
- 「実行中」になればOK

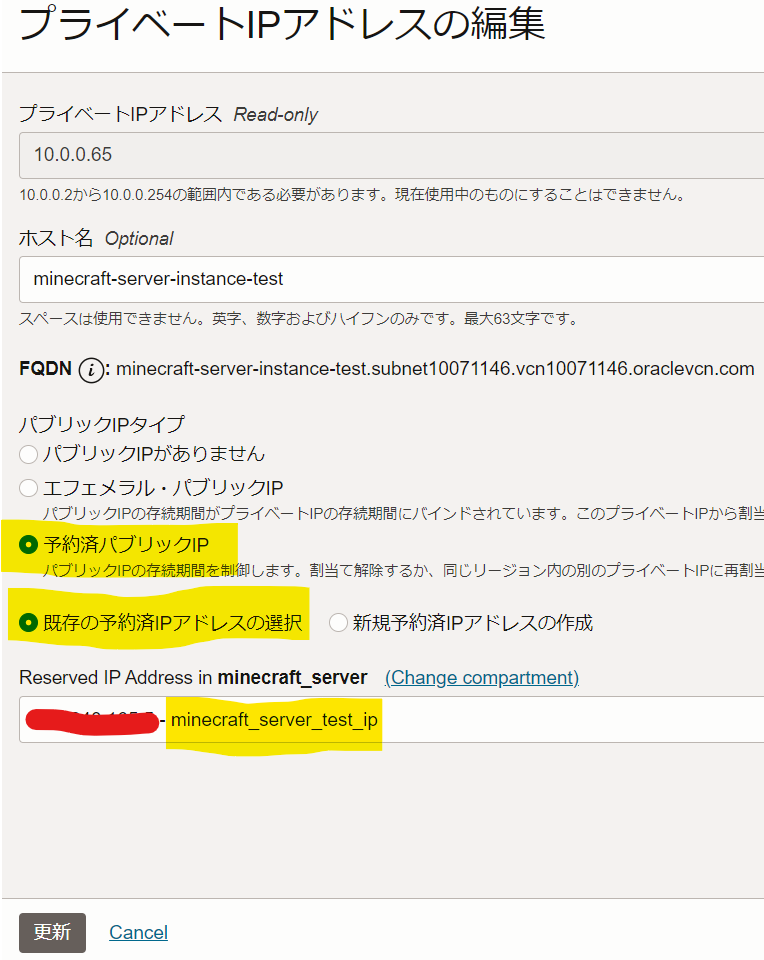
固定IPを取得
- IPが変わるとクライアント側で接続先を変更する必要があり、面倒なので固定します
- ネットワーキング→IP管理→予約済パブリックIP
- 「パブリックIPアドレスの予約」を押下して必要情報を入力
- 予約済みパブリックIPアドレス名: わかりやすい任意の名前(本記事では
minecraft_server_test_ipとしました) - Create in Compartment: ↑で作成したコンパートメントを選択
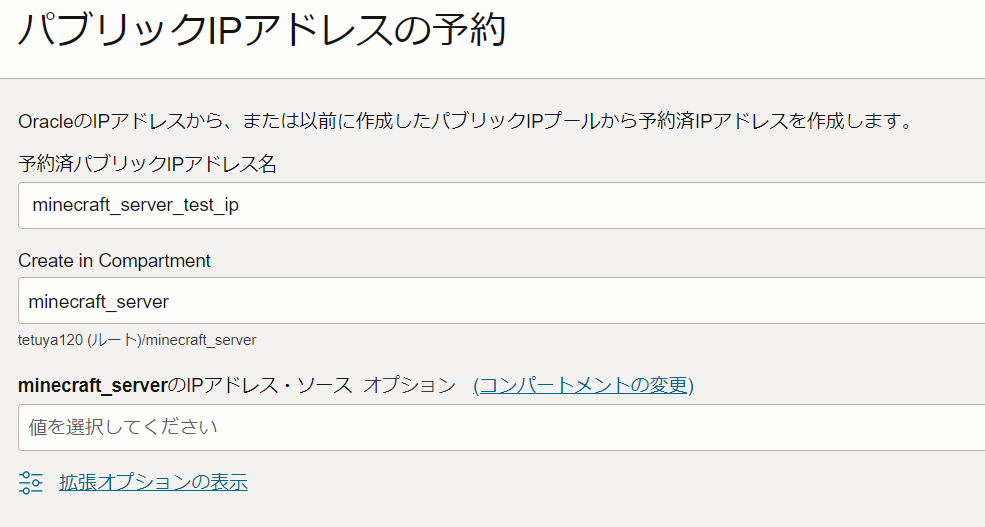
- 予約済みパブリックIPアドレス名: わかりやすい任意の名前(本記事では
- パブリックIPアドレスの予約押下
- 一覧に作成した名前で表示されていればOK
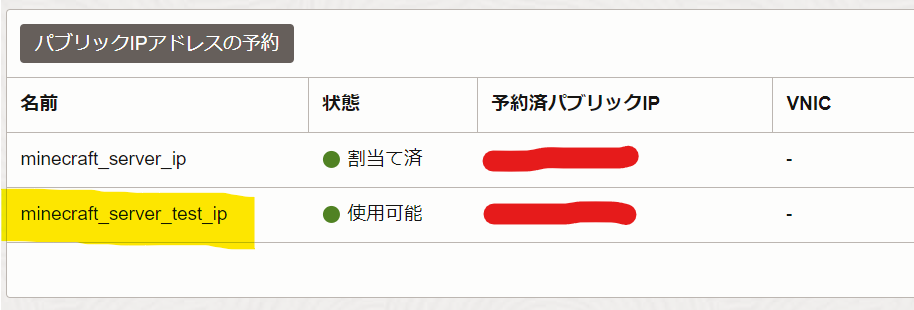
※このIPにクライアントから接続することになります
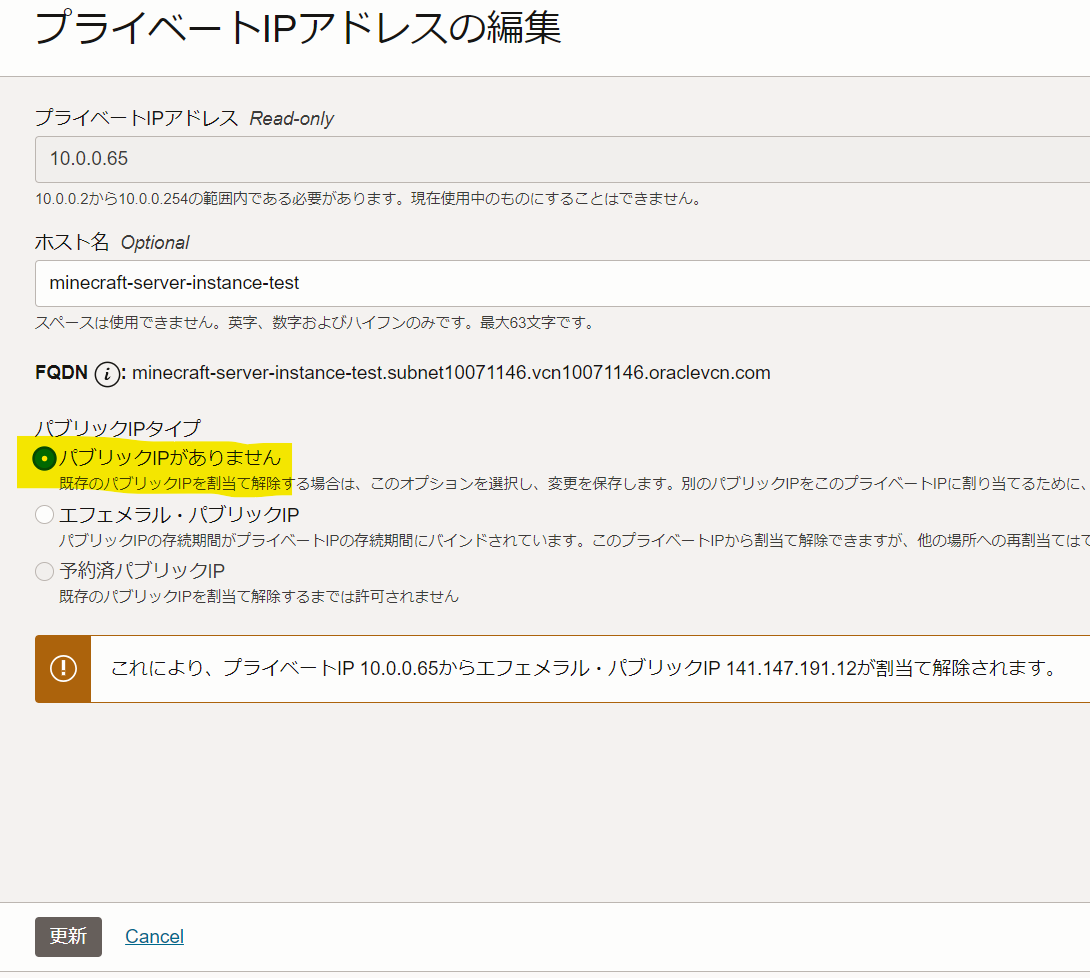
インスタンスのIPを固定
- ↑で取得した固定IPをインスタンスに設定します
- インスタンス画面を表示し、 下の方にある アタッチされたVNICを押下、選択。
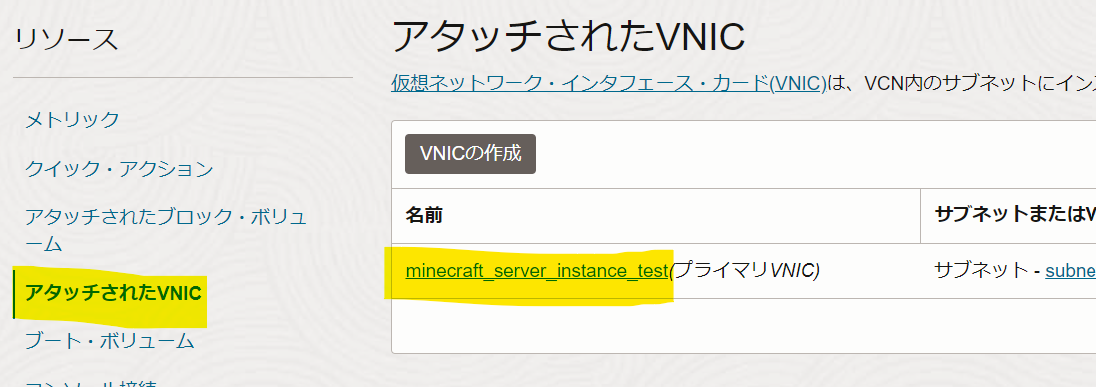
- 下の方にあるのですごくわかりにくいので注意
- 下の方にある「IPv4 アドレス」を押下し、
︙から「編集」を押下 - パブリックIPの割り当てを解除 → 更新
- 再度、
︙から「編集」を押下 - 「予約済みパブリックIP」が選択できるようになっているので、取得した予約済みIPアドレスを選択 → 更新
- インスタンスに戻って、プライマリVNICのパブリックIPv4アドレスが取得した予約済みIPアドレスになっていればOK

インスタンスのポート開放
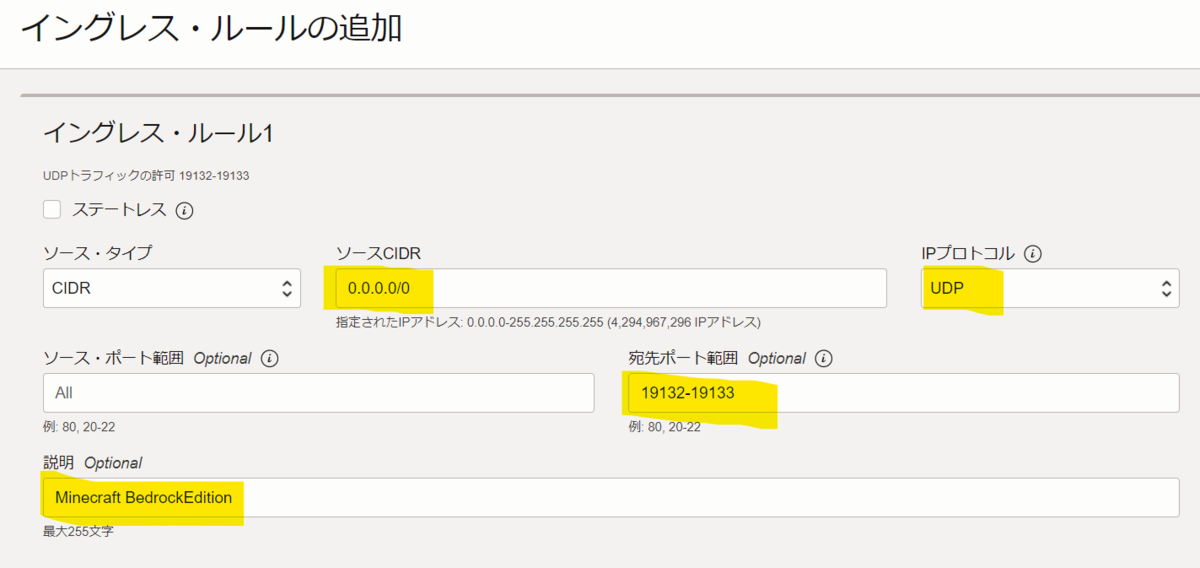
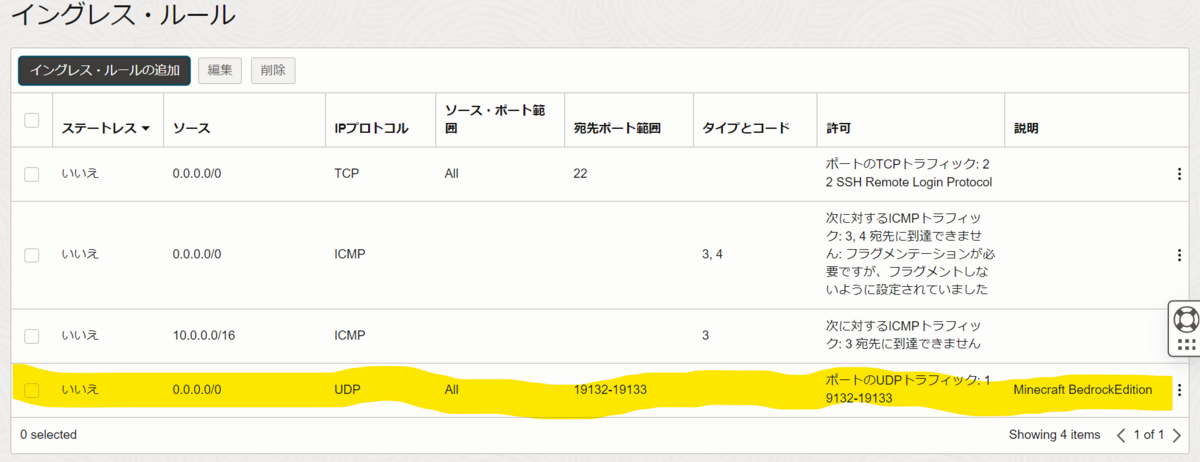
- クライアントからサーバにアクセスできるようにポートを開放します
- インスタンス画面を表示
- プライマリVNIC内のサブネットを押下
- イングレス・ルールの追加を押下
- 必要な情報を入力
- 一覧に作成されたルールが表示されていればOK

インスタンスへのSSH接続

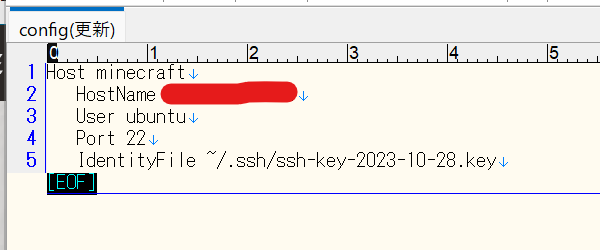
Host minecraft_test HostName 192.0.2.0/24 User ubuntu Port 22 IdentityFile ~/.ssh/ssh-key-2023-10-28.key
- インスタンスへ接続
- ターミナルを開く
- Windowsの場合は
Windowsキー + R→cmd入力
- Windowsの場合は
ssh ${↑のconfigで指定したHost}とコマンドを入力- 例:
ssh minecraft_test
- 例:
- はじめて接続する場合にはfingerprint確認しろと出るので
yesと入力 - 以下のように接続できればOK
- ターミナルを開く


インスタンスの設定
sudo apt update sudo apt upgrade -y

上記のようなメッセージが表示された場合は「15」入力し、一旦抜けてから sudo shutdown -r now と実行し、サーバーを再起動。
※カーネルのバージョンが変わるので、再起動しろよっというメッセージです。(意訳) ※再起動すると当然ssh接続は切れるので、再度sshで接続してから次に進みましょう
sudo apt install vim zip unzip ufw cron -y
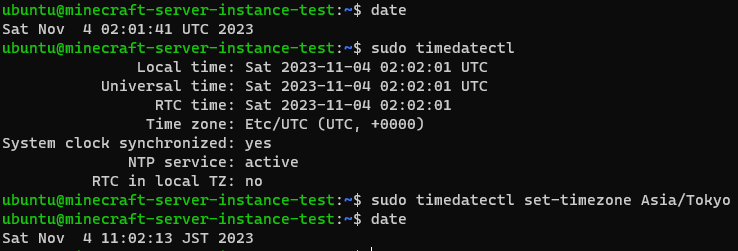
sudo timedatectl sudo timedatectl set-timezone Asia/Tokyo
sudo ufw status verbose sudo ufw default deny sudo ufw allow 22/tcp sudo ufw allow 19132/udp sudo ufw allow 19133/udp sudo ufw enable sudo ufw status verbose

Minecraftをインストール
- 現在のバージョンのURLを確認
- 以下にアクセスし、最新のバージョン、URLを取得取得
- www.minecraft.net
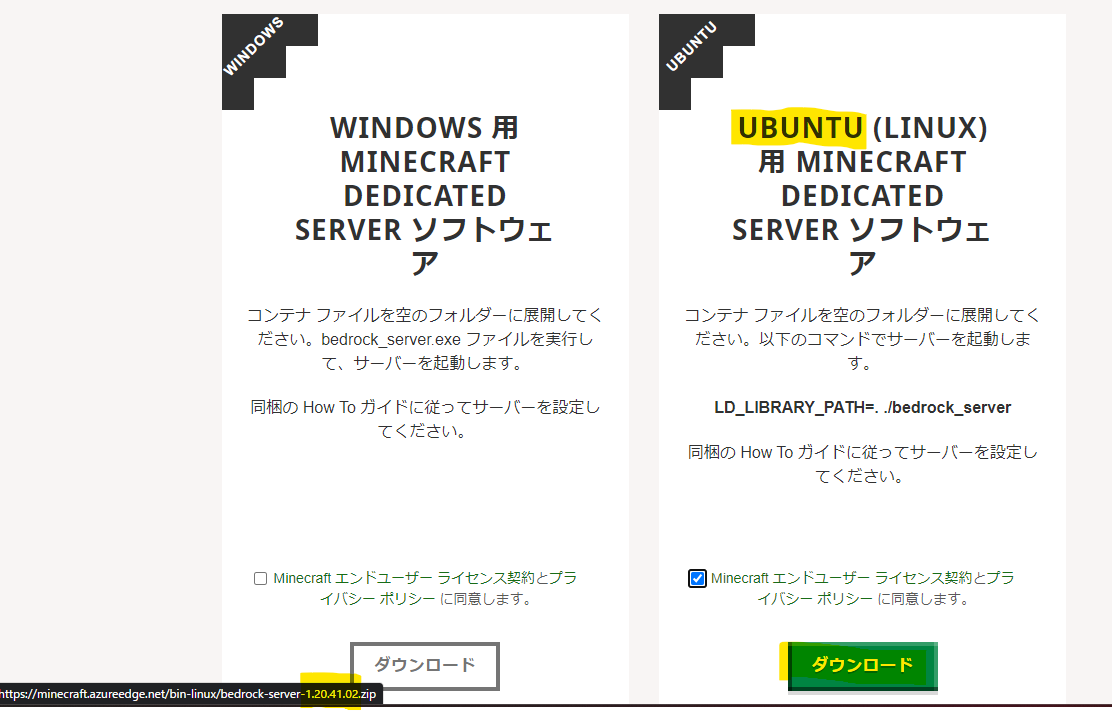
- 上記のキャプチャの場合だと、「1.20.41.02」、「
https://minecraft.azureedge.net/bin-linux/bedrock-server-1.20.41.02.zip」 - ※もっと良いバージョン確認の方法があったら教えて欲しい
- 以下にアクセスし、最新のバージョン、URLを取得取得
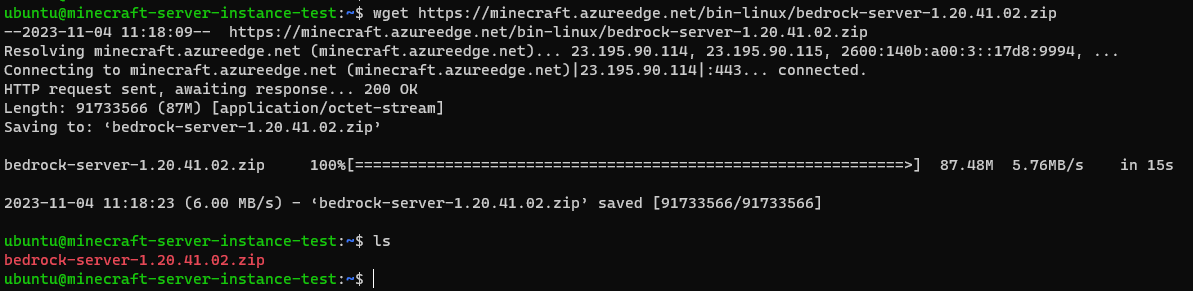
- モジュールを取得
wget https://minecraft.azureedge.net/bin-linux/bedrock-server-1.20.41.02.zip- URLは上記で取得したURLを使用する
- モジュールを解凍
unzip bedrock-server-1.20.41.02.zip -d ./minecraft- minecraft というフォルダ内に解凍します
- 以下のようになっていればOK
- 試し起動
- minecraftフォルダに移動
cd minecraft
- 起動
LD_LIBRARY_PATH=. ./bedrock_server
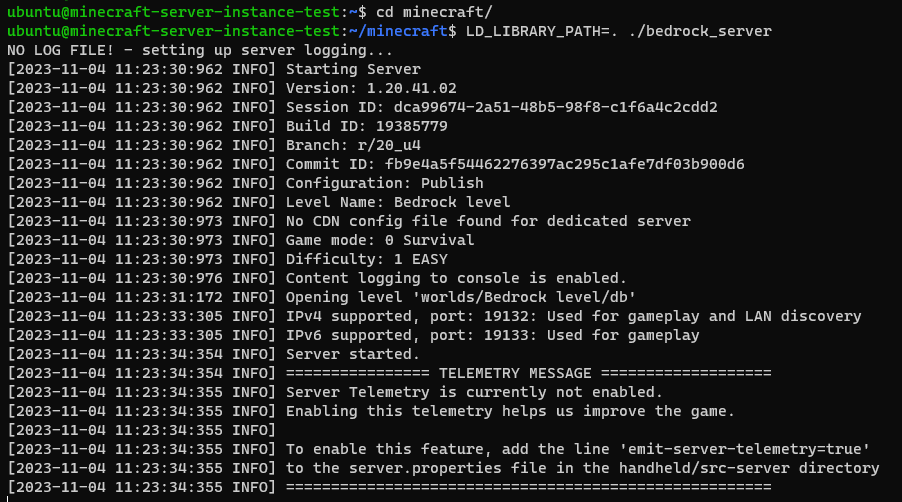
- minecraftフォルダに移動
- 試し接続
- ログを確認
- サーバー側に以下のようにログが出ていればOK

- お試し起動終了
- サーバー側で
CTRL + Cで終了 
- サーバー側で

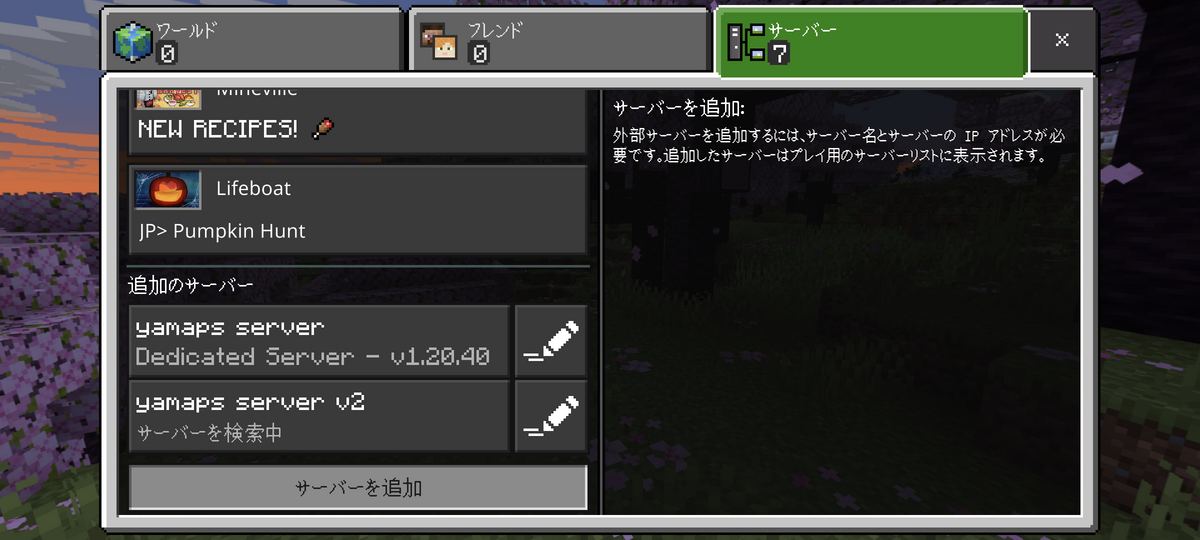
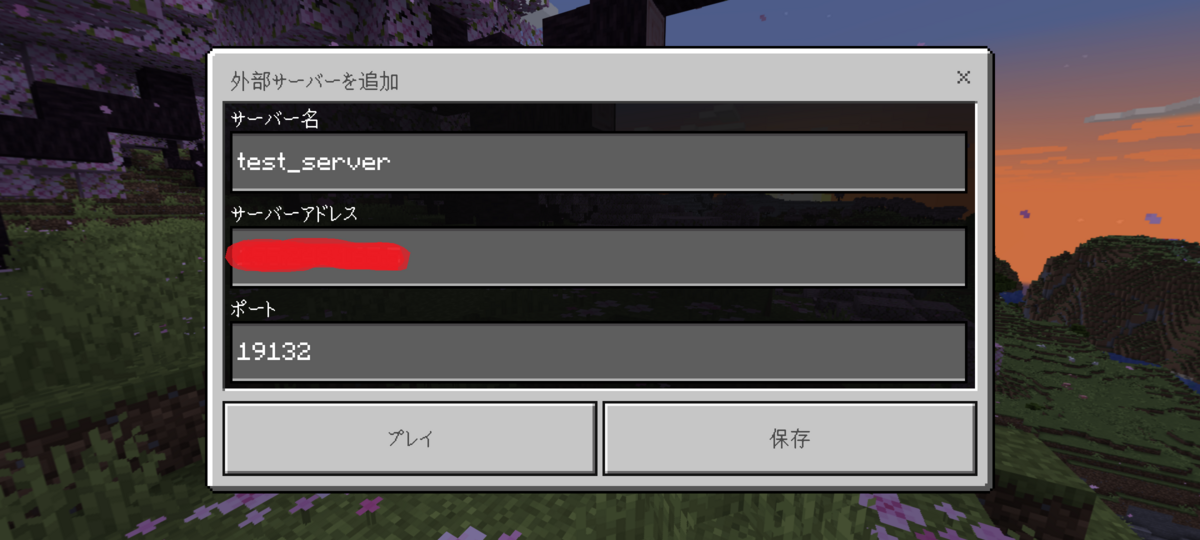

起動設定
- 現在の方法でも普通に遊べますが、サーバー側で起動が必要ですし、ssh接続が切れたらMinecraftは止まってしまう
- よって、サーバー起動時に自動で起動するように設定を行う
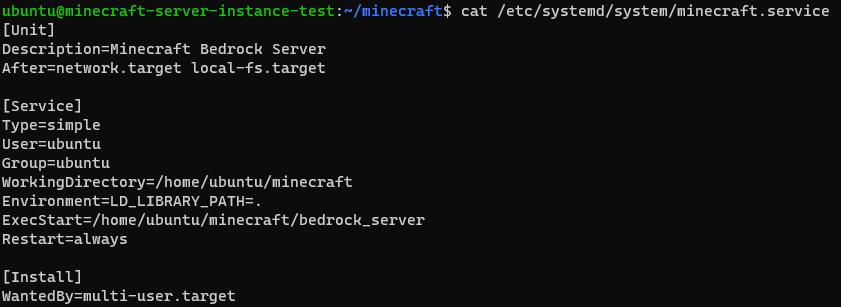
- systemdの設定ファイルを作成、編集
sudo vim /etc/systemd/system/minecraft.service
- 以下のように記載
- 一通りオプションは調査していますが、気になる人は自分で調べてください
[Unit] Description=Minecraft Bedrock Server After=network.target local-fs.target [Service] Type=simple User=ubuntu Group=ubuntu WorkingDirectory=/home/ubuntu/minecraft Environment=LD_LIBRARY_PATH=. ExecStart=/home/ubuntu/minecraft/bedrock_server Restart=always [Install] WantedBy=multi-user.target
- systemdに設定
sudo systemctl daemon-reload sudo systemctl enable minecraft sudo systemctl start minecraft

- サーバーを再起動して、Minecraftが起動するかを確認
sudo shutdown -r now
- サーバー再起動後に、クライアント(AndroidとかのMinecraftアプリケーション)から接続できたらOK
Nintendo Switch から接続する
はじめに
- 基本的にXbox One、Nintendo Switch、PS4/PS5 などは任意の外部サーバーに接続することはできません
- そのため、本体側の設定を変更する必要があります
- なお、色々なblog等でこの設定が紹介されていますが、これは↓を使用しています。この人は無償で提供してくれていますので、GitHubアカウントを持っている方は★、そうでない方は寄付等で感謝を示しましょう!!
手順
※英語ですが、本家の動画ですので一番わかりやすい。 ※どうしても日本語が良い、テキストでほしい場合には switch minecraft 外部サーバー - Google 検索 とかで調べると、色々出てきますが、情報古かったり間違っていたりするのでおススメはしません
未成年アカウントで外部サーバーに接続する場合
はじめに
- 未成年は外部サーバーにアクセスすることができないように制限されています
- MinecraftはMicrosoftアカウントでログインする必要があり、Microsoftアカウントの年齢で制限されます
- Microsoftではゲーム系の設定はXboxで管理するらしいので、Xbox.com 側で設定することになります。
手順
※概要だけ記載します。画面や設定内容は時期によってかなり変わるようなので参考程度にしてください
- MicrosoftアカウントでFamily設定をし、親アカウントで子アカウントとFamilyになります
- Xboxにマイクロソフトアカウントでログイン
- Xboxプロフィールを表示

- ※広告除去ツールを入れているとエラーになるので注意(少なくてもAdblock Plusだとエラー)
- プライバシー設定
- 子のアカウントを選択し「Xbox Series X|S、Xbox One、Windows 10 デバイス オンライン セーフティ」
- 「マルチプレイヤー ゲームへの参加」を許可
- 【未確認】プライバシーの「Xbox Live 以外のユーザーが音声やテキストで通信できるようにする」も許可する必要があったかもしれない
- 接続できればOK
- 参考


Minecraft設定
最低限の設定を記載しておく
server.properties- Minecraftのサーバー側の設定
allow-list=trueにして下記のallowlist.jsonを有効にしておく
allowlist.json- サーバーにアクセスすることができるユーザー一覧
permissions.json- Minecraft内の権限の設定
- 身内でやるなら
operatorが良いと思う
バックアップについて
- Worldsフォルダがあれば復旧可能
- 復旧経験あり
- 加えて、上記の設定ファイル3種をバックアップしておけば良い
Minecraftバージョンアップについて
はじめに
- Minecraftはサーバー側とクライアント側のバージョンが一致していないとプレイすることができない
- Switch等だと自動でバージョンアップが行われるため、サーバー側も常に最新バージョンにアップデートする必要がある
- が、統合版の最新バージョンを知るためのAPI等を見つけることができなかったので、クライアント側でバージョン差異でエラーになった際に手動でバージョンアップをすることを想定している
- バージョンアップは最新のバージョンを取得、解凍した後に、Worldsと設定ファイルを上書きすればOK
スクリプト
以下のリポジトリのREADME参照 github.com
Minecraft のバックアップについて
はじめに
- バックアップはworldsフォルダのみを取得する
- 本来は設定ファイルも取得した方が良いが、大した設定していないので無視している
- 容量削減のため1週間以上古いバックアップは削除している
- 動作しているサーバーに直接バックアップしているため
- 本来はCloud Storageにバックアップするのが良い
スクリプト
以下のリポジトリのREADME参照 github.com
Windowsで起動しているDev Container内からGitのリモートリポジトリに操作を行うと Permission denied が発生する場合の対処方法
事象

解決策
- ホストのssh-agentのバージョンを上げる
winget install Microsoft.OpenSSH.Beta- 記事執筆時にはBetaしかなかったが
winget search opensshで正式版が出ているか確認すること
- Dev Containerのドキュメントにも注意書きがある
詳細の前置き
- Dev Containerはただのコンテナなので特に指定をしないとSSH接続の際に使用される秘密鍵は共有されない
- 共有されないということはGitHub等のリモートリポジトリを対象としたpull、pushなどもできない
- 開発時に使用されることを目的としているDev Containerとしては著しく体験が悪いのでssh-agentを使用して秘密鍵をDev Containerと共有する
- Windowsの管理者権限が必要なので注意
- 詳細: Visual Studio Code Remote Development Troubleshooting Tips and Tricks
- 管理者権限をもらえない環境の場合は
.sshをマウントすれば可能- ※当然鍵がそのままコンテナに入るのでセキュリティ的には注意が必要
- 参考: [add] mount .ssh folder by yamap55 · Pull Request #12 · yamazaki-seiya/nobiru_kun · GitHub
詳細とか詳細な手順とか
事象が発生することを確認
- DevConatainer内で
git pullを行うことで発生 - privateリポジトリなのでpullで発生している
- publicリポジトリだとpushで発生するはず(自分のリポジトリでも発生する)
ちなみに python:3.11.4 のコンテナで発生した。( Docker Hub )
ssh-agentのバージョンを確認
- ssh-agentはsshについてくるものらしいので、sshのバージョンを確認
- ホスト(Windows)でopensshの最新バージョンを調査
winget search openssh
winget search openssh
- ホスト(Windows)にopensshをインストール
winget install Microsoft.OpenSSH.Beta- wingetが動作しない場合には直接GitHubから取得してインストール

- sshのバージョンを確認

- ※私の環境だとインストールを行ったターミナルではだめだったので、別のターミナルを立ち上げて確認
- Dev Container内に秘密鍵が共有されていること、エラーが発生しないことを確認



参考
memo
- Gitコマンドではなく、
ssh-add -lとかの結果を記載する方が本質的だったなと思った
チームとして大切にしたいと思っている3つのこと

はじめに
リーダーとしての立場になり、どのようなチームを作り、どのように進んでいきたいのかをメンバーに明確に伝えなかったことが、一部のすれ違いの原因となりました。 今までも近いポジションを担っていたことはありますが、暗黙的な理解に助けられていたことを改めて知った次第です。 今まで一緒に働いていた方ありがとうございます。
そんなこともあって、私がチーム、組織の中心となる際に何を大切しているか、どういうチームを作っていきたいかというものを言語化して書いておこうと思った次第です。 今も昔も全てを実現できているかというと難しいところではありますが、意識していきたいなと思っております。
ただし、これは私の個人的な視点であり、会社全体や特定のチームの公式な目標やKPIとは異なることに注意してください。
※なので、会社内に閉じるのではなく個人のblogに書いて公開しているわけです。
大事にしているもの
- 何でも自由に言う
- 背景を意識する
- 市場価値を上げる
何でも自由に言う
チームで大切にしたいことの一つ目は、「何でも言える」環境の実現です。 新人であろうとベテランであろうと、全てのメンバーが自由に意見を出せる環境を作りたいと思っています。 年齢や経験年数に関係なく、皆が「こうした方がいいんじゃない?」、「これはなぜこのような形?」、「理由はわからないけど筋が良くない気がする」と自由に提案できる場です。 これはネガティブな意見でも同じです。「今担当のXが楽しいのでYはやりたくない」、「Zは好きではない」といったそれだけでは自分勝手と受け取られるような意見を言える場としたいです。
全ての意見が採用されるわけではないですが、それぞれの意見はチーム全体が多様な視点から問題解決や改善策を考えるための重要な資源です。
「何でも言える」ことができるためには、互いを尊重する信頼関係を築くこと、心理的安全性を高く保つ必要があります。 自由に発言することで不要なストレスを抱えることなく、自分たちの能力を最大限に引き出すことができると考えています。
背景を意識する
次に大切にしたいことは「背景を意識する」ことです。 これは仕事をただこなすのではなく、なぜその仕事をする必要があるのか、その背後にある意図や目的を理解し、行動することを指します。 タスクをただ達成するだけではなく、それが何のために必要なのかを常に考えることで、より効果的な方法がないか、あるいはそのタスク自体が本当に必要なのかを見極めることができます。
この考え方はプロジェクトの全体像を理解し、より具体的で質の高い提案や意見を出すための基盤となります。 また、背景を理解することで、自身の仕事の価値を感じ、その結果、モチベーションの維持にも繋がると考えています。
市場価値を上げる
最後に大切にしているのは「市場価値を上げる」ことです。 これは自分たちがどのようなスキルや知識を身につけることで、自身の価値を市場でも認められるようにするかという視点です。
特定のプロジェクトやサービスに深く関わる専門知識は、その分野や組織内では非常に価値がありますが、市場全体での価値とは必ずしも相関しないことが多いです。 一方、コミュニケーション能力や問題解決力のような広範なスキルはどの組織でも求められ、業界や役職によって求められる具体的なスキルや知識も、それらが広く利用される範囲であれば、高い市場価値を有しています。
もちろん、自社のプロジェクトやサービスに精通することは重要ですが、それと同時に、なぜそのような設計が選ばれたのか、他にどのような選択肢があったのかといった、背後にある理論や理由を理解することが重要だと考えています。 これにより、汎用的な知識を身につけ、自分の市場価値を上げることができます。
最後に
私がチームとして大切にしている3つのポイント、「何でも自由に言う」、「背景を意識する」、「市場価値を上げる」について書きました。これらはチームの行動指針となり、共に成長し、問題解決を進めていく上での鍵となる要素ではないかと思います。 最後に、これを読んでくださった方が少しでも参考になる点を見つけられたら、自身のチーム作りに活用していただければと思います。
そして、この機会にお知らせです。 現在、私たちと一緒に働き、これらの価値観を共有し、挑戦を共にする仲間を募集しています。 興味がある方は、以下のWantedlyまたはTwitter(DMでも可)までお気軽にご連絡ください。
仕事はもっと適当にやればよい
はじめに
- 本記事は社内報に寄稿した内容を転載したものです
- 許可済み
- 私がどのように考えてお仕事をしているかを書いた文章であり、一般的なものかどうか、他の人がどう思うかは意識しておりません
- こんな事を考えて仕事している人もいるのかーくらいに読んでいただければと思います
- 「適当」は「適切」、「適度」といった、ちょうど良いという意味と共に「いい加減」や「雑」といった意味もあります。タイトルはその両方を含みます
仕事は誰のためにやるのか
自分のために決まってる。これは大前提。
会社のためにやるということも、給料、経験、人脈、やりがいとか何でも良いですが、それが自分にとって得るものがあるからですよね。家族のため、子どものため?それは家族や子どもが喜んでいることが嬉しい、育っていることが嬉しいということがあるのではないかと思います。社会のためというのも同じでしょう。
難しいことは置いておいて自分は自分のために生きていて、自分のために仕事をしているという事をしっかりと意識しておいたほうが良いと思います。忙しいときに何のために働いているのかを考えるという話がよくありますが、そういった時に思い出しましょう。*1 得るものがなければそこで働く意味はない。
仕事を楽しくやる
とは言っても、やりたい仕事をやれるなんてことは滅多にありません。やりたい仕事をやらせてもらえるまでやりたくないと断り続ける?流石にそこまで神経図太い人はいないでしょう。いい感じのところで妥協するのが人生であり、世の中です。ではどうするのか。仕事はすべて決まっているわけではありません。目的、ゴールは決まっていてもそこに到るための方法は幾つもあり、その仕事にアサインされたあなたには大なり小なり裁量が与えられているはずです。
売上向上という目的だけが決まっている場合には、どのように売上を達成すれば良いかに裁量があるかもしれません。システムを作ることが決まっているならプログラム言語やフレームワークを選択できるかも。システムのある機能を担当するならば画面構成やクラス設計、手動テストであればテストの実施方法。どんな仕事でもやり方、方法がすべて決まっているわけではありません。仮に決まっていても手足、頭を動かすのは人なので効率的に動かすなどの裁量は与えられています。
与えられた裁量の中でいかに楽しくやるか。これが適当にやるということ。
つまり、仕事とは与えられた目的を達すればよい。それをどのように達するか、それを楽しめるかどうかがポイントです。
仕事外で楽しむ
仕事外と書くとプライベート時間となりそうですが、そういうことではなく業務時間内の話です。与えられた裁量の中で楽しくやるといってもその裁量の範囲ではどうしても制限が大きくなり、楽しみは少なくなりがち。であるならば、仕事外(ここではPJ外という言い方が適切か?)で楽しくやる。
仕事は利益を得るためにお金を払うという話であり、逆に言うと目的から外れていても利益になればよいという話ではないか。勿論契約で約束されたことは達成する必要がありますが、そもそも目的がぶれているなんてことはよく聞く話。目的が外れていて利益になるものであれば何でもよい。何でも良いのであれば自分が楽しいことをやればよいじゃない。
「不利益にならなければよいし、利益になればなおよし」の精神で自分がやりたいことをやればよいと思っていて、私が常駐先でLT会やワークショップ、勉強会等々やっているのはこれが原点です。
評価
仕事は言われたこと、求められていることだけではなく、それに加えて何を行ったかによって評価されます。ただ、100求められていて120行うのは難しい。100と120の差を評価者がわかるのか?っという問題もあります。ただ、別のことを10行う、0→10は難易度が抑え目のことが多くわかりやすい。わかりやすいということは目立ちやすいということであり、目立ちやすいというのは評価されやすい。
また、常駐するPJの場合にはお客さんの評価だけではなく、個人評価にも反映されやすいです。なぜならば常駐のPJは一緒に仕事をしていない上司から評価を受けることが多いですが、私のように工数100%で長く常駐(4年ほど常駐していました)していると、「いつも通りよくやっています」のように評価されがちです。その時にわかりやすい指標は評価する側からしてもとても評価しやすいようです。
言いたいこと
結局言いたいのは、タイトルにある通り「適当にやればよい」ということ。まじめにお仕事するのも大事ですしやらなければならないですが、もっと肩の力を抜いて柔軟性をもって働いていくとお仕事も楽しくなるのではないかなということです。せっかくお仕事するなら楽しくやりましょう!
文章に入られなかったのでここに書いちゃいますが、「許可を得るな謝罪せよ」*2という言葉も好きです。基本的に不利益にならなければやっちゃってよいと思うのですよね。
*1:忙しいときに考えるのでは遅い。なぜならば、そんなこと考える余裕がないから。
*2:この言葉は超訳という話もありますが。 https://twitter.com/t_wada/status/752674410482446336
Windows PCセットアップメモ
はじめに
- 本記事はWindows PCを購入した際のセットアップメモです
- 個人的な設定がかなり含まれています
- キャプチャは異なる可能性があるので参考程度にしてください
- 随時更新していく予定
環境
Windows初期設定
- Microsoftアカウントでログイン
- 初期設定時にローカルアカウントを作る裏ワザもあるようだが、いつ塞がれるかわからないため、ここではMicrosoftアカウントで初期設定後にローカルアカウントを作成し、切り替える方法を使用する
- ローカルアカウントで初期設定する方法もメモ
- 特に特筆すべき項目はないため割愛
- デスクトップが表示されたら次へ
アカウント切り替え
- Microsoftアカウントでユーザを作ると、ホームディレクトリがメールアドレスの先頭5文字となる
- アカウントが「abcdefg12345@outlook.com」だった場合、「c:\Users\abcde」っとなる
- ホームディレクトリを変更する方法は提供されていない
- 頑張ってやればできるっぽい方法はどこかで見た
手順
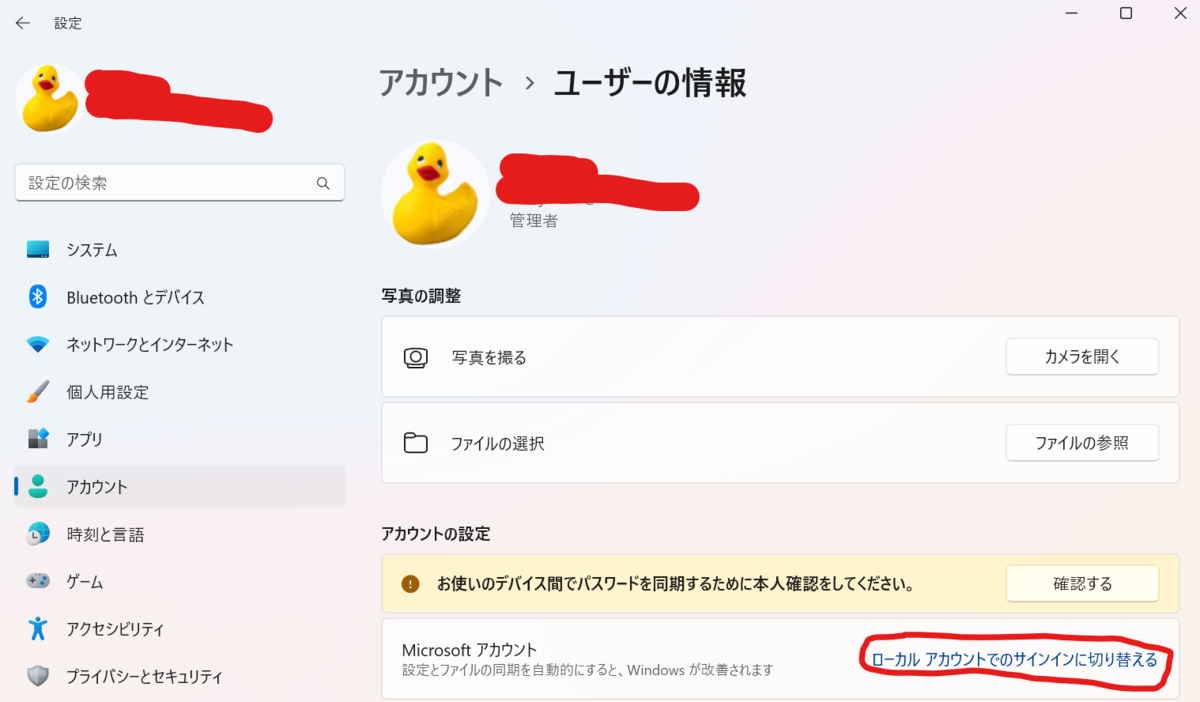
- 現在ログインしているMicrosoftアカウントのユーザをローカルアカウントに切り替える
- Windowsキー → 「アカウント」で検索 → アカウント情報 → ローカルアカウントでのサインインに切り替える
- Windowsキー → 「アカウント」で検索 → アカウント情報 → ローカルアカウントでのサインインに切り替える
- 警告が出るが初期設定のみであれば無視してスキップでOK
- Windowsキー → 「他のユーザー」で検索 → その他のユーザーを追加する → アカウントの追加
- 「このユーザーのサインイン情報がありません」をクリック
- 「Microsoftアカウントを持たないユーザーを追加する」をクリック
- ユーザー名とパスワード、秘密の質問を設定 → 次へ
- ユーザー名とパスワードを入力すると下に秘密の質問が出てくる
- ユーザが作成されればOK
- 作成されたユーザを権限を管理者に変更
- Windowsキー → ログインユーザークリック → 作成したユーザクリック
- 設定は割愛。ログインしてデスクトップが表示されればOK
- Windowsキー → 「アカウント」で検索 → アカウント情報 → Microsoftでのサインインに切り替える
- Windowsキー → 「他のユーザー」で検索 → 初期設定時に作成したユーザを削除







セキュリティアップデート
- Windowsキー → 「Windows Update の設定」で検索 → 更新プログラムのチェック
- 言われるがままに再起動を駆使してすべての更新を適用
- ドライバとかアップデート
IME設定
- タスクバーのIME右クリック→設定→キーとタッチのカスタマイズ
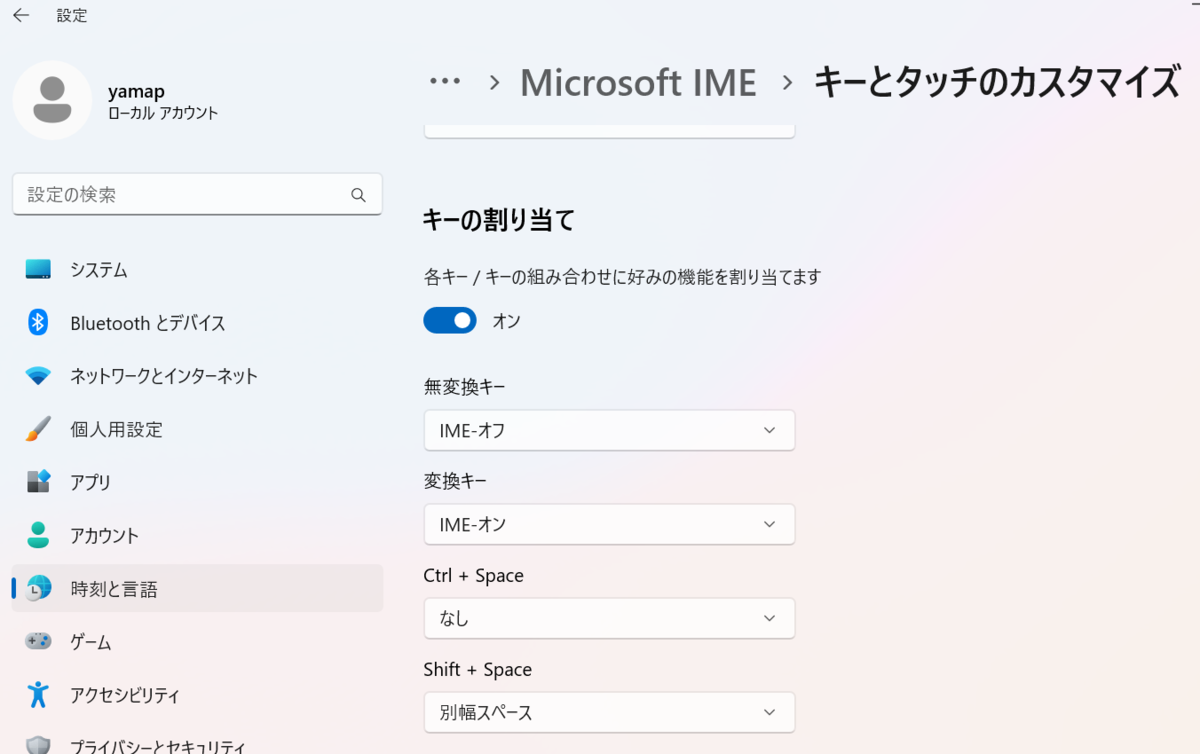
半角全角を切り替えるのが面倒なので、無変換でIMEオフ(半角)、変換キーでIMEオン(全角)となるようにする。これにより今全角モードなのか半角モードなのか気にする必要がなくなるので全人類にオススメの設定。(今が全角モードだろうが半角モードだろうが、無変換押せば半角になる)
※昔は結構深いところに設定があった気がする
フォルダオプション
- Windowsキー → 「フォルダオプション」で検索 → 表示タブ
- ファイルとフォルダーの表示 → 「隠しファイル、隠しフォルダー、または隠しドライブを表示する」に切り替え
- 「登録されている拡張子は表示しない」からチェックを外す
タスクバー
- タスクバーに常駐している必要ないアイコンを右クリック → 「タスクバーからピン留めを外す」
- タスクバーの何もないところを右クリック → タスクバーの設定 → 「タスクバー項目」から必要のないものをオフに変更
wingetでツールをインストール
wingetとは
インストール
- コマンドプロンプト開く
Windowsキー + R→cmd入力 →
- 下のコマンドを順番に入力
winget install Google.Chrome winget install Microsoft.VisualStudioCode winget install Docker.DockerDesktop winget install Git.Git winget install Python.Python.3.10 winget install "windows terminal" --source "msstore" winget install SlackTechnologies.Slack winget install WinMerge.WinMerge winget install -e --id Spotify.Spotify winget install NickeManarin.ScreenToGif winget install voidtools.Everything winget install stnkl.EverythingToolbar winget install Microsoft.OpenSSH.Beta
※Pythonはバージョンを確認
※OpenSSHは正式版が出ていないか確認( winget search openssh )
その他ツールをインストール
- サクラエディタ
- Releases · sakura-editor/sakura · GitHub
- 「Win32-Release-Installer.zip」的なものを取得
- 解凍してインストーラ実行
- 「SAKURAで開く」オプションチェック
- clibor
- ダウンロード | Clibor
- 解凍したら
c:\tools配下に配置
ツールの設定
- Chrome
- VS Code
- Git
git config --global core.autocrlf falsegit config --global pull.rebase falsegit config --global core.pager "LESSCHARSET=utf-8 less"git config --global user.email hogehoge@users.noreply.github.comgit config --global user.name yamap55
- GitHub
- 鍵を作成して公開鍵をGitHubに登録
- GitHub アカウントへの新しい SSH キーの追加 - GitHub Docs
- ssh-agent
- サクラエディタ
- オプション「タブバーを表示する」にチェック
- マクロ追加
- clibor
Windowsキー + R→shell:startupでスタートアップフォルダを開いてそこにショートカットを配置- ※設定に「スタートアップに登録」があったのでこちらでもよいと思われる
- 起動して設定変更
- 履歴を1000件
- 10分ごとに履歴保存
白源(font)導入
HackGen_NF_vX.X.X.zipを取得- 解凍 → 必要なフォントを右クリック → インストール
Windowsのテーマ変更
- Windowsキー → 「ダーク」で検索 → システム全体でダーク モードを有効にする

WSLの設定
wsl --update wsl --set-default-version 2 wsl --install -d Ubuntu-20.04
※22.04はGUIが付いてくるらしいので20.04を選択
WSLのUbuntu
sudo apt update sudo apt upgrade -y sudo dpkg-reconfigure locales
sudo update-alternatives --config editor
shellの設定
wget --progress=dot:giga https://raw.githubusercontent.com/git/git/master/contrib/completion/git-completion.bash -O ~/.git-completion.bash wget --progress=dot:giga https://raw.githubusercontent.com/git/git/master/contrib/completion/git-prompt.sh -O ~/.git-prompt.sh chmod a+x ~/.git-completion.bash chmod a+x ~/.git-prompt.sh
~/.bashrc の末尾に以下を追記
source ~/.git-completion.bash
source ~/.git-prompt.sh
export PS1='\[\033[1;30m\]\t\[\033[0m\] \[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\[\033[1;30m\]$(__git_ps1)\[\033[0m\] \$ '
スクリプトの設定
- ダウンロードフォルダを片付けるスクリプト
タッチパッド無効
※Thinkpadはトラックポイント(赤ポチ)があるため無効にする